
A common mistake when using embeddings in ML applications
Applied ML #13

Most ML-first companies today use embeddings to build the recommendations feed on the homepage [e.g. Google/Youtube] or the search / autocomplete experience [e.g. Microsoft, JD.com] Also for people interested in learning how to build an end-to-end search system on AWS-ElasticSearch with equality attributes and embedding search please read this really well written document on search by the Scribd team.
Typically, these embeddings need to be computed by a neural network (see Figure 2). The neural network is periodically retrained (see Figure 3 and 5). That results in different versions.
A common mistake when using embeddings is trying to match the user/query embeddings from one version of the neural network model with the item embeddings generated from another version of the model.
The search / recommendation results might be poor quality unless the versions of embeddings are kept in sync.
In this article we will look at a sample application that is dependent on embeddings. We will see where problems could arise and will see how to avoid this version mismatch error.
Where are embeddings used?

Embeddings are used in multiple parts of the search / recommendation stack. In this article we will focus on the retrieval step. As shown in Fig 1 above, the user / query embedding can be used to retrieve the results from potentially millions / billions of candidate items in under 50 milliseconds (p95).
To generate embeddings we need to train a neural network model
To compute the above mentioned user and item embeddings, one needs to train a two-tower or dual-encoder model ( see below )

These neural network modules can then be used to go over all the users and items respectively and generate their corresponding embeddings.
MLOps: Now that we have explained the two-tower model, we will see what is involved in retraining the two-tower model and all the problems we can face in operational aspects of using a new version of the embeddings.
Four steps of computing a new embedding version

As shown above, the steps are:
train a new version of encoders.
A completion of training should trigger a downstream task of actually computing the user and item embeddings for all users and items.
Once user embeddings have been computed they need to be uploaded to a KV store, something like {user_id -> user_embedding}. This is needed to fetch the user embeddings in Step 2(a)/2(b) of Fig 1 above.
Once item embeddings are computed, if these are being used for retrieval, the quantization and population of a new version of a similarity search service is needed.
Version mismatch
During the t4 to t7 period in Fig 3, it is possible to query the similarity search service with user embeddings that are from a different version.

Unfortunately embeddings of the same item from two distinct versions of the encoder might not have any similarity with each other. Hence unless we take care to maintain the version number, the search/recommendation results would be poor in quality.
Solution
The solution is to preserve the version number of the user/query embedding generator and to use item embeddings from the same version. If that is not available, we should degrade the service gracefully by using other retrievals.
The key-value store would then be changed to retain the last 5 user embedding versions:
user_id -> [(user_embedding, v5), (user_embedding, v4) …]
This way, during serving, we could query with the highest version number embedding. If we encounter an error then we could query with the next highest version number and so on. This assumes that version numbers are an increasing sequence. This also assumes that the similarity search service supports version numbers.
Separate model retraining from embedding refreshing frequency
It is clear that retraining the two-tower model frequently could lead to operational problems. Why do it then? What we are looking for is for embeddings of users and items to reflect the recent changes.
For instance if a user has listened to true crime podcasts in the past but has been searching for podcasts this week, then it stands to reason that the search/recommendation system should get better results if the user embedding is updated with recent data.
For query embeddings this problem is less severe. If you are searching “sports” on a video website for instance, the embedding of the query “sports” might not change in character too much every day. However, results might be 3X better with personalization for broad/categorical queries. Hence a stale user embedding could still hurt. (This paper is an example for quantitative impact of using stale embeddings)
Stale item embeddings is likely to hurt performance in both search and recommendation tasks. Items have dynamic features like number of purchases of an item in the last 7 days, that should ideally be factored into embedding updates.
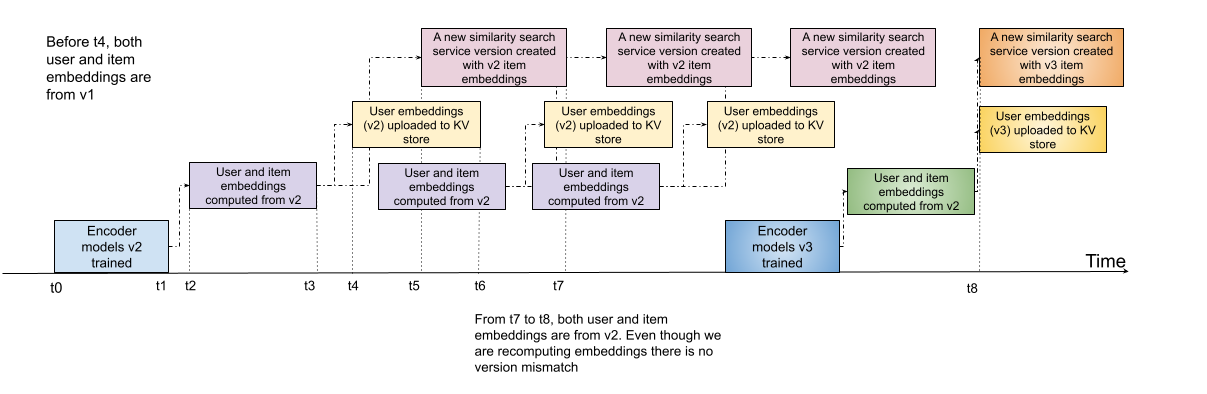
We have decoupled training the model and updating the embeddings. If we run inference multiple times with the same model (e.g. 3 times in Fig 5 above), then the embeddings are still compatible with each other.
Conclusion
Refreshing embeddings and retraining encoder ML models are important for good performance.
While doing so, embeddings must retain the version number of the encoder model.
Care must be taken to only match the query/user embedding with the item embeddings generated from a decoder of the same version.
Other notable items this week
OpenAI recently released a Triton that writes extremely efficient GPU program code from python code. GPU programming is really difficult. It is easy to make mistakes. It is hard to debug and it is extremely hard to write efficient GPU programs that extract every bit of the machine’s abilities to deliver performance. Seemingly, Triton does that translation at near human-expert level and much better than average-human performance!
This might unlock wider adoption of GPU programming. For a number of applications like similarity search, it has been difficult to write optimized GPU code to speed them up. Triton could unlock greater GPU adoption.
Disclaimer: These are my personal opinions only. Any assumptions, opinions stated here are mine and not representative of my current or any prior employer(s).