

Early (Stage) Ranking in recommender systems
We look at "early (stage) ranking", why it is needed, what is success for it and end with a baseline implementation of it.

Why is an Early Ranker needed

Most modern recommender systems are multi-stage:
Retrieval or Candidate generation which produces say about 2000 candidates
Ranking which chooses say about 50 from these 2000.
Typically, the ranking stage needs to be very accurate in surfacing the most relevant items at the top. That need for precision translates into the ranker being a big model that is compute intensive. Both from a latency and capacity usage perspective, it helps to break ranking into two stages, an early ranker and a final ranker. An early ranker (ER) is used to prune the set of candidates down for final ranker.
Please find references to early ranker in industrial large scale recommender systems in Related Papers #2 and #4 below.
Measure of success
Business metrics
Minimize overall compute / capacity usage
Minimize latency
Maximize topline metrics like end user satisfaction
What that translates to
Hence, an early ranker needs to be both good at
not removing candidates that final ranker would likely have pushed to the top.
removing for easy negatives.
Approaches
1. Same metric and data as Final Ranking
Usually final ranking is optimized for
a rank-order metric like NDCG
or a precision oriented metric like: Normalized Binary Cross Entropy (or an equivalent estimate like Watch Time used in YT). These are estimates purely about each item at a time.
For instance, in e-commerce recommendation this could be
Probability of buying item
Probability of clicking to see details of item
2. Recall @ K with Final Ranker
Once in a while send all candidates to final ranker and
“True top 200” is the top 200 chosen by final ranker.
Recall@200 for the early ranker is the percentage of the “true top 200” candidates that appear in the early ranker's top 200.
It is perhaps not fair to compare a metric like normalized binary cross entropy and a ranking metric like nDCG.
Separate Estimator and Ranker metrics

I recommend separating the 3 functions of the early ranker to have a clearer definition of success for each. It will be easier to optimize them since each will have a clear measure of success.
Deduplication
Ensures that we have a single item even if multiple candidate generators sent the same recommendation.
Estimator
Computes the per-item user-value estimates for each item.
Note that this does not actually reduce the number of candidates, hence the name “estimator”.
Ranker/Top-K selector
Actually cuts down the ~2000 candidates to ~200 as needed. Uses the estimates from the estimator stage.
An illustrative baseline implementation (no estimator)
An illustrative baseline implementation for instance is just to deduplicate and randomly select top K (say 200) candidates.
When might you NOT need an Early Ranker
If the number of candidates being ranked are very few.
For instance if you have around 20 “Discord Nitro” promotions to show and you want to rank the best one at the top, just the final ranker should work.
If you have only one candidate generator.
This might be controversial but if you have one candidate generator, then I think it is better to build an early ranker into the candidate generator like “Related papers [1]” does.
Coming soon
In the next article, we will expand on the baseline implementation to develop a smart pipelined model driven early ranker.
Related papers
In [Revisiting Neural Retrieval on Accelerators], authors build a two stage “retrieval”. They have a traditional two-tower candidate generator (see H-indexer below). However, unlike a regular nearest neighbor candidate generator like TwHIN or Fig 3 of DNN for YT Recs, they take the top M candidates from the two-tower first stage and apply an in-GPU early ranker to select m candidates. Here m is perhaps a hundredth of M.
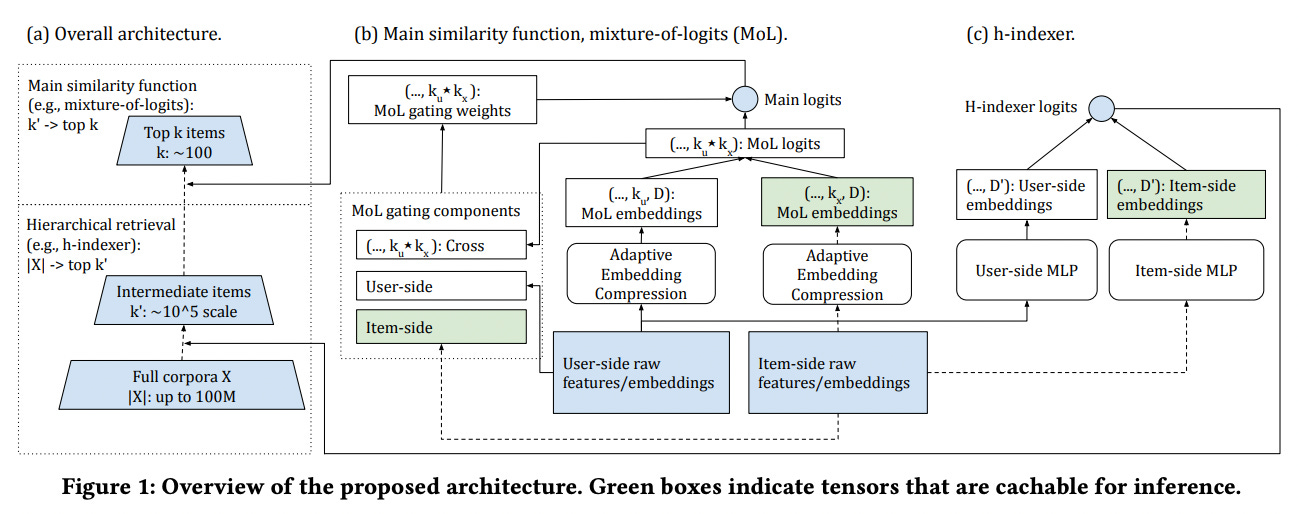
While [TwERC: High Performance Ensembled Candidate Generation for Ads Recommendation at Twitter] is mostly about graph based candidate generation, it also shows an Early Ranker (they call it “light ranker” as well) in the pipeline and how for some candidates it might be prudent to bypass it.


What to optimize in multi-stage recommender systems is not just a problem for early rankers. It is a problem for retrieval as well.
In [Stochastic retrieval conditioned ranking], the authors claim:
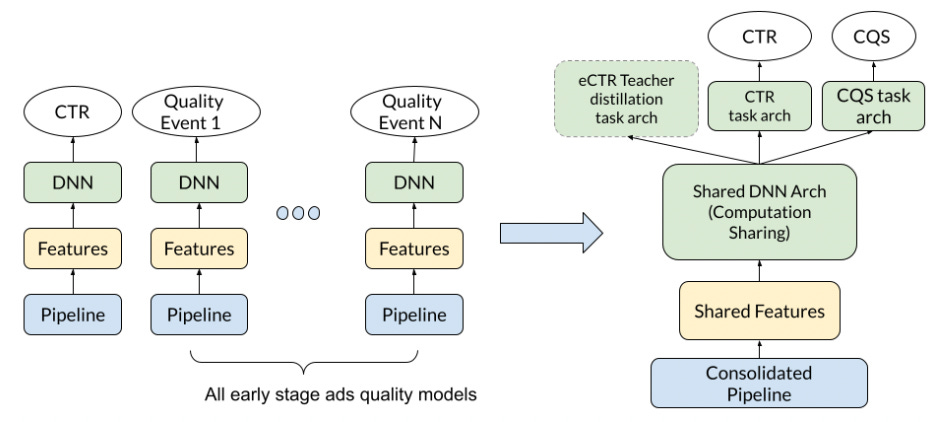
”A popular assumption in the community is that the early-stage retrieval model should be optimized for recall of the top 𝑁 documents, while the late-stage learning-to-rank model should be optimized for a desired user-centric precision-oriented metric, such as NDCG. However … we show that improving the retrieval recall does not always lead to better reranking performance. … Instead, we should aim for high precision as long as sufficient relevant documents are retrieved.”In [Towards the Better Ranking Consistency: A Multi-task Learning Framework for Early Stage Ads Ranking], authors from Meta show where early ranking is in Meta’s ads recommender stack

Fig 6: An early ranker between retrieval and final ranker reduces the number of items ranked by final ranker. and how the output of the early ranker are task estimates.

Fig 7: As mentioned in section “Separate estimator and ranker metrics”, it is a common design for the early ranker neural network model to come up with the same pointwise estimates that a final ranking model estimates.

Disclaimer: These are the personal opinions of the author. Any assumptions, opinions stated here are theirs and not representative of their current or any prior employer(s). Apart from publicly available information, any other information here is not claimed to refer to any company including ones the author may have worked for or been associated with.
Gaurav, this is such an amazing series on RecSys!!
Great series on Recys Gaurav! Thanks for writing it :)
Just nitpicking a little, I think the NDCG cannot be optimized directly as it is a non-differentiable metric. To overcome this, some modified form of NDCG should be used. Google proposed ApproxNDCCG here:
https://dl.acm.org/doi/pdf/10.1145/3331184.3331347