

Friend Recommendation Retrieval in a social network
From Graph Search to Deep Neural Two-Tower Models



Introduction
Social networking platforms, e.g. LinkedIn:PYMK and IG:SA, help users find friends on the platform and forge meaningful connections. Traditionally, an effective approach for friend recommendations has been to suggest "friends of friends" i.e. using mutual connections as a proxy for relevance. This article begins by exploring graph search as a way to implement this baseline and traces the evolution of friend recommendation systems beyond this foundational approach. It concludes with a discussion of Two Tower models, which leverage compute power and data to drive greater accuracy in retrieval.
Graph Search: The First Principles Approach

To implement “Friends of Friends,” a scalable approach, e.g. FB:Unicorn, has been to create a graph datastore of relationships that enables counting the number of two-hop paths between a source user and other nodes. Ranking nodes by the number of two-hop paths is akin to ranking by mutual friend count, providing a basic but efficient recommendation mechanism.
Improving Graph Search with Weighted Paths
Besides scaling up one can use weighted paths in the graph between viewer and recommended friend to refine results. By assigning weights to edges (friendship connections) and nodes (users) based on various attributes, platforms can calculate a "path score" for potential connections. These scores are derived from the cumulative weight of paths ending at a given node, allowing the platform to rank potential connections by relevance. (Gong et al. 2017)
For weighting, one might consider incorporating factors like interaction frequency of the users in the edge, connection recency (how recently that connection was made), common interests, or shared communities (for example - we may assign a ⅓ edge weight multiplier if two users have had shared a conversation in the last 7 days, effectively increasing the likelihood of sourcing this candidate). The hypothesis here is that a user with multiple paths of highly weighted connections is more likely to be a relevant friend recommendation. Different weighting hypotheses can be validated through online experimentation, making this approach more robust. This weighted-path method aligns with traditional graph search while enhancing it with more granular social signals.
Embedding-Based Approaches: DeepWalk and Node2Vec
Credit to where it is due. Two seminal papers that demonstrated the feasibility of embedding techniques are DeepWalk[4] and Node2Vec[5]. These methods sample paths and learn latent representations (embeddings) of nodes based on their connectivity patterns, capturing the structure of the network more efficiently than traditional graph search. This embedding-based approach effectively reconstructs paths in the graph, with similar embeddings indicating a higher likelihood of connection. Sharing two images of DeepWalk below to build intuition.


DeepWalk, which uses random walks on the graph to generate training samples, laid the foundation for this approach. Node2Vec extends it by enabling biased sampling, which helps control the balance between exploring global and local structures. These methods allow platforms to efficiently compute similarity scores between users, which are then used to make friend recommendations.
Clustering with Spectral Analysis
Spectral clustering on the friendship graph is another approach to friend recommendations, particularly useful for identifying groups of users likely to share interests or connections. In this method, clusters are formed based on dense areas in the graph, often revealing latent communities. Nodes with many paths ending on them, but without direct connections, are likely in the same cluster as the source node, making them promising friend recommendations.
Though historically computationally complex, some recent approaches to spectral clustering have been more efficient: AROPE, NetSMF, ProNE ([8], [9], [10] respectively). For example, AROPE is computationally linear with respect to graph size. NetSMF claims to have taken “only” 24 hours to train on a network of 10s of millions of nodes.
Spectral clustering can yield high-quality recommendations by grouping users into meaningful social clusters, but due to its high computational complexity it is no longer popular for generating production-scale friending recommendations. It is although very useful to reduce network interference bias in A/B tests for friending recommendation models - core idea is to leverage spectral clustering to identify dense user-groups and assign the entire group to either treatment or control [14]. Running A/B tests at a coarser granularity (at a user-group level instead of at a user level) helps reduce network interference in friending systems.
Challenges remain though; at the billion node scale, these approaches could still be problematic and model fine tuning with updated data could be challenging.
Two Tower Models: An Extension of Clustering Approaches
Two Tower models ([7], [1], [2]), also the workhorse in ads or video recommendations, are a natural evolution from clustering techniques, as they aim to learn representations for each user independently, which are then used to predict likely friend connections. In this architecture, one "tower" processes the features of the viewing user (e.g., the one looking for new friends), while the other tower processes features of the candidate user. The model is trained to maximize the similarity between embeddings of users who are friends and minimize it for non-friends.
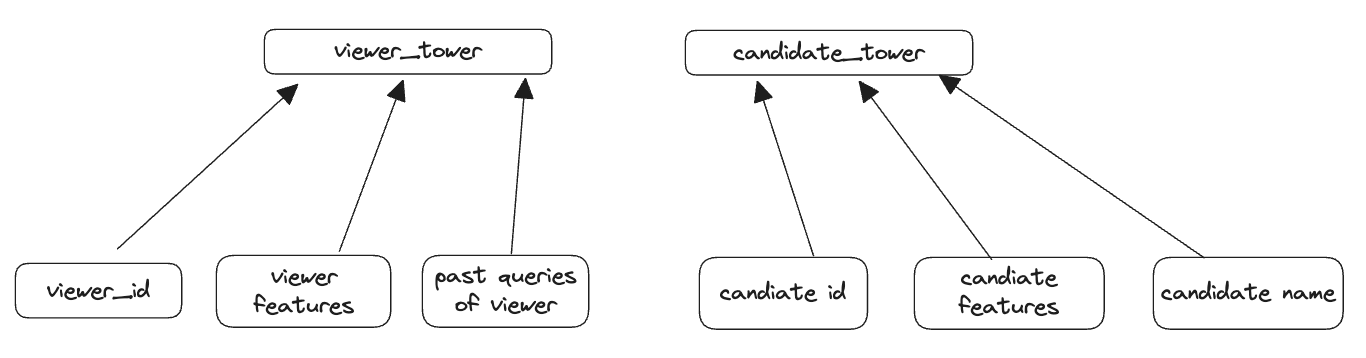
Pros of Two Tower Models over Graph Search
Two Tower models offer several advantages over traditional graph search:
Nuanced Relationship Capture: These models can learn complex, latent relationships by processing a variety of features and considering recency or frequency of interactions, which graph search approaches struggle to incorporate effectively.
Multi-Task Potential: Since Two Tower models capture user relationships in embeddings, they are flexible enough to be used for tasks beyond friend recommendations, like predicting message frequency or engagement with friends' content. This multi-task ability leads to enhanced alignment between the sourced candidates and the final ranking model; they can both be trained to value the same interactions and training samples.
Scalability: Unlike graph search, which can become computationally intensive at scale, Two Tower models are optimized for distributed computation, making them well-suited for large networks.
Compute-Enhanced Accuracy: Two Tower models allow state-of-the-art architectural techniques, like transformers or mixture-of-experts, to complement increased training data, boosting accuracy in retrieval.
Two Tower models for friend recommendations is a deep area of research and there is a lot more to talk about it. For instance, the Multi-task reference above is a rich and impactful vein of exploration.
Priming Friend Recommendations with Existing Connections
One effective way to enhance a Two Tower model for friend recommendation is to prime the training dataset with existing friends. By including all current connections as positive samples, the model can better understand what a "friendship" looks like, helping it differentiate friends from non-friends more effectively. This approach enriches the embedding space, offering the model a broader understanding of social connections and improving its performance in predicting new friendships. This can be even more useful if the embedding table of user and target ids is shared with other sparse features that leverage userids. During inference using K-nearest neighbors, you will need to filter out current friends from new friend recommendations. Open research question: Can this be avoided? Can we directly train embeddings which are close for new friends but aren’t for existing friends?
Using Impact Weighting for Topline Alignment and to Prevent Embedding Collapse
A risk in embedding-based approaches is that the embeddings may collapse into a low-rank representation, meaning they do not adequately capture the uniqueness of individual users. Collapsed embeddings are often overly fixated on high-activity "power users," limiting the model's ability to recommend relevant connections for a broader user base. Put another way, the neural net is learning the simplest solution to the challenging problem.
To address this, we need to force the model to avoid the simple solution by making the loss depend less on these “easy” training examples. Try weighting your examples by inverse square root of number of friends of user and target in the Two Tower model training data [3]. This will focus more on users who are likely to derive greater value from new friendships. By emphasizing these users, you not only mitigate the risk of embedding collapse but also develop an embedding space that aligns more closely with business goals. This approach improves the quality and diversity of friend recommendations, supporting the creation of meaningful connections for a wider range of users.
Embedding collapse is a deep topic, e.g. [6], and we will share a separate post on it.
Blueprint for Adding Two Tower Models to Graph Search Implementations
If you currently have a friend-of-friends implementation and are considering adding Two Tower-based retrieval, it can be a challenging transition. Two Tower model development is a new skill for many teams, and without a proper validation path, delivering top-line results may take time. The following trajectory is suggested:
Optimize Offline Hit Rate: Improve the model to achieve an offline hit rate at rank 1 for a batch size of 1024, targeting a hit rate of 0.7.
Begin with Offline Inference: Before deploying embedding-based retrieval in production, start with offline computations.
Compute embeddings for both user and candidate towers.
For each user, generate the top 100 candidates.
For each candidate, generate the top 100 users, and cross-reference in SQL to produce candidate lists for users.
Validate Recall: Use candidate lists to evaluate recall against ground truth (organically added friends) in offline experiments. This recall should be measured at the retrieval stage, as the ranking model has not yet been trained for this distribution.
Develop Ranking Features: Using the lists from the retrieval stage, develop ranking features for friend recommendations. Validate that these features improve performance by reducing offline normalized entropy.
Generator efficiency: After step 4, see if the impression rate of candidates from your two tower model is more than the retrieval distribution rate of your generator. This would mean that candidates from your generator are considered better by the ranking layer than alternatives.
If the above is not happening, it is too soon to expect topline gains. You might want to iterate.
More generally about embedding based retrieval, Snap’s retrieval team found ([15]) adding Embedding Based Retrieval (EBR) increased friendships made from friend-recs by 5% to 10%, and the overlap of these with Graph-Search (Friends-of-Friends) is low. In a follow up ([16]) they found an 11% improvement in friends-made-with-communication. This can be seen as a hybrid of two approaches. Here they sample (up to) 5 of the friends of the viewer and find nearest neighbors with them.

Conclusion
The journey from graph search to Two Tower models represents a significant advancement in friend recommendation systems, enabling platforms to deliver recommendations that are both accurate and meaningful. While graph search techniques provide a solid foundation, the advent of embedding-based and deep neural models like Two Tower architectures has opened new avenues for friend retrieval, allowing social networks to capture the nuances of human connections in increasingly sophisticated ways. As these systems continue to evolve, they will foster richer, more personalized experiences that mirror the dynamic nature of social relationships.
Though we discuss Two Tower models in the Friending use case, this architecture lends itself towards efficient, scalable ad & video recommendation, facial recognition, and more generally - learned embedding database search.
References & Further reading
[2407.13218] LiNR: Model Based Neural Retrieval on GPUs at LinkedIn
Candidate Generation in a Large Scale Graph Recommendation System: People You May Know
[1609.02907] Semi-Supervised Classification with Graph Convolutional Networks the authors propose a layer-wise propagation rule that includes a normalization factor 1didj , where di and djare the degrees of the nodes connected by an edge. This normalization helps to stabilize training by scaling the contributions of each node's neighbors according to their degrees. This motivation was used above in the weighted paths idea.
[1403.6652] DeepWalk: Online Learning of Social Representations
[1607.00653] node2vec: Scalable Feature Learning for Networks
[2310.04400] On the Embedding Collapse when Scaling up Recommendation Models
GitHub - gauravchak/two_tower_models: Repo to guide implementation of Two Tower models
AROPE - Arbitrary-Order Proximity Preserved Network Embedding
[1906.11156] NetSMF: Large-Scale Network Embedding as Sparse Matrix Factorization
FAISS - Facebook AI Similarity Search
Graph Convolutional Networks | Thomas Kipf | Google DeepMind
[1903.08755] Using Ego-Clusters to Measure Network Effects at LinkedIn
Embedding Based Retrieval in Friend Recommendation (Snap 2023)
Improving Embedding-Based Retrieval in Friend Recommendation with ANN Query Expansion (Snap 2024)
Disclaimer: These are the personal opinions of the author(s). Any assumptions, opinions stated here are theirs and not representative of their current or any prior employer(s). Apart from publicly available information, any other information here is not claimed to refer to any company including ones the author(s) may have worked in or been associated with.
 | A guest post by
|
 | A guest post by
|