
Give new creators a fair shot (through recommender systems)
ML in recommender systems #9

Most recommender systems (recsys) today have “rich get richer” characteristics, in the sense that they favor established, popular content creators over unknown, new creators. In this post we will see how to build recommender systems that encourage new creators.
Why is it important for the platform to encourage new creators?
New creators 👉🏽 fresh content and perspectives 👉🏽 captures changing users’ interests.

We will also build recsys from a new perspective, such that it is able to run parallel experiments for each item. It will also coordinate distribution of items to maximize the value for the creators. (For example, if two superhero movies are being released, it would be best to not release them the same weekend!)
Inspiration
This post is inspired by:
Tiktok’s approach to recommendation based on interest graph and not social graph. Eugene’s blog post, and podcast episode on it (below) are quite insightful, and perhaps better reads than this post.
Controlling fairness and bias in ranking (Best Paper Award at SIGIR 2020) … by researchers at Cornell (check out video on ACM page). The authors mention two problems with naive ranking mechanisms, (a) that estimated relevance is often a function of which items / creators have received exposure to users in the past and hence ranking systems suffer from rich get richer problems (b) amongst items with similar relevance, ranking systems can develop unfairness across a group. For instance, they show that on a website with blue and green articles, even if 51% users like green articles, the website will learn to show green articles to everyone.
Google Research: How to use a reinforcement learning / latent bandit (NIPS 2020) approach to quickly learning what the user is looking for. (Hint: by clustering item embeddings learned by a Two-Tower model / Graph Neural Network and then using a Thompson Sampling approach over clusters.)
Why is this hard?
Why is it difficult to make recsys that is fair to new items by unknown creators while not compromising quality?
Why is it difficult to recommend based on interests and not based on whom you follow or which channel / seller / publisher you have consumed content of before?
Most recommender systems today heavily rely on social / reputation links. Relying on a social graph or a creator reputation graph helps the recsys weed out poor quality items with high confidence. The recommendation is “lower risk” to the user. It also makes the process of offering users an explanation of “why” the recommendation was made easier… “Because I follow user X” or “because I have watched videos from channel Y before.”
On the other hand recommending in a way that places new creators at an equal footing to established creators is risky since there is low confidence in the system if this will engage the user or what is its ‘reputation’ .
The magic of Tiktok’s recommendation system
Encourages content creation
Recommends based on interests and not a social graph or reputation charts
Bets a lot on each recommendation. Each recommendation gets the full screen. You can either engage or swipe. To visualize how bold it is to build a UX like that, imagine going to Amazon / Etsy and seeing one item at a time! You can either heart it, add to cart, or swipe it away.

An image of a Tiktok video from Eugene’s post. Eugene mentioned that this was the most popular TikTok ever with 34.1 million likes. Notice, the full screen recommendation.

Recommendations = a massive parallel experiment

Eric’s message, in the talk, was that a startup is an experiment designed to find out what customers want.
A recommender system (recsys) is similarly a coordinator of experiments. The system is constantly being presented with new items by creators. The recsys needs to design experiments to figure out which of these items would be liked by the users. Let’s try to itemize what tasks this recsys would need to do:
With each new item the recsys needs to figure out what it is. This is usually done by a multi-label classification model trained with expert data.

An approach to finding labels or tags for each new item. Please note that while labeling has been described as a standalone task here, most state of the art recommender systems try to learn an item embedding that is shared between labeling and recommendation tasks. Then the recsys needs to figure out whether this item is any good in its category. Assuming the majority of items are not very good, you probably want to start with the users who are most likely to like this particular item. If they don’t like it, then this item probably is not very good.
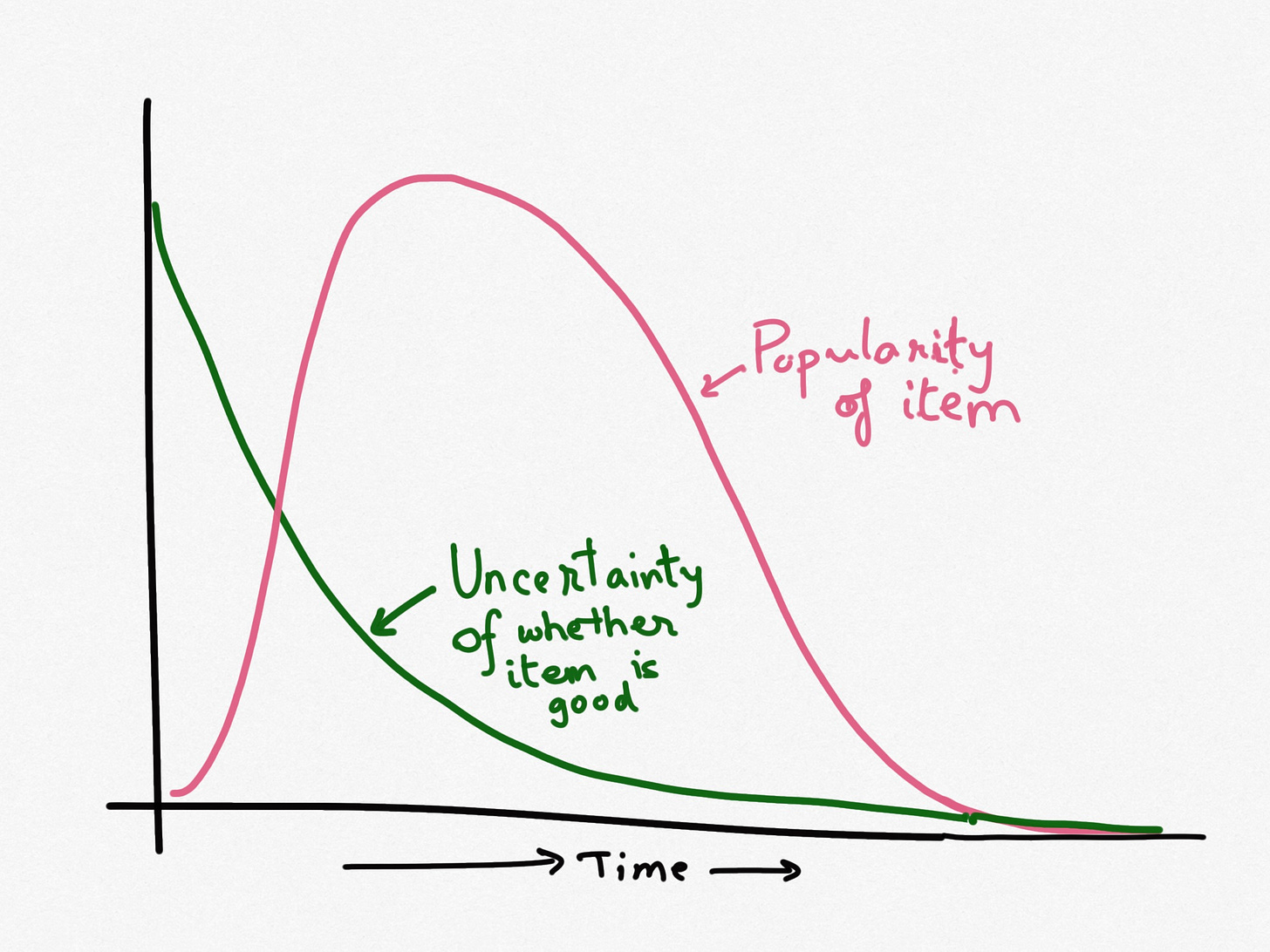
Upon experimentally showing this item to users, the uncertainty about its potential goes down, while it gets the chance to be popular. The platform will need a second viral loop to reap the most reward of its successful experiments, like “top trending items”. In machine learning literature this is known as “Exploit” while showing new items to test the waters is knows as “Explore”. The recsys could be wrong in its audience selection. Hence it needs to allow for some way to correct its mistakes. Perhaps on mapping the item the recsys found that it is good for audience 1 “definitely”, audience 2 “should be” and audience 3 “now we are stretching it”. To allow for mistakes, in addition to sampling users from audience 1, it could perhaps sample a few from audience 2.
Based on the reception on the initial audience the recsys should decide what other validation steps to run. For instance, the recsys could look out for above average reception and expanding the targeting, detect new implicit categorization based on which users are interacting with the item, etc.
Coordination across items: On finding something that is being well received by an audience, the recsys need to give it enough runway. The recsys needs to coordinate recommendation of items in a way that does not cause choice fatigue, and could also save inventory for future.

The reason why recommender systems find it hard to find out about a new item is that they tend to show similar items to a large number of users. Hence the cost of a poor recommendation becomes high. To find out about a new item, the recsys needs to change things for a select few users for this new item.
Based on the evidence the recsys has so far, it doesn’t know if this new item is a great fit for any of your users. Purely based on estimated probability of being liked, perhaps for all users in audience 1, this item might only deserve to be at position 100 in their feed. However, using the term in the sense Eric meant above, you will not “learn” much about this item if you place it at position 100 for all users.
There is a lot more to learn about an item by a few users seeing it at the top of their feed than thousands of users finding the item at position 100 in their feed.
Value model
What is the value of a recommendation? Traditionally recsys builders have focused on the demand side:
Value (item to a user) = Probability(user will like item)
Let’s call that “User (side) Value”. The idea being that if users like the item, they pay with transactions (ecommerce), spend time (social networks) , click to learn more (online ads) etc.
But is that all? What about creators?
Creator side Value(item, user, creator) = Probability(user will like item) * Incremental happiness of one more like (creator)
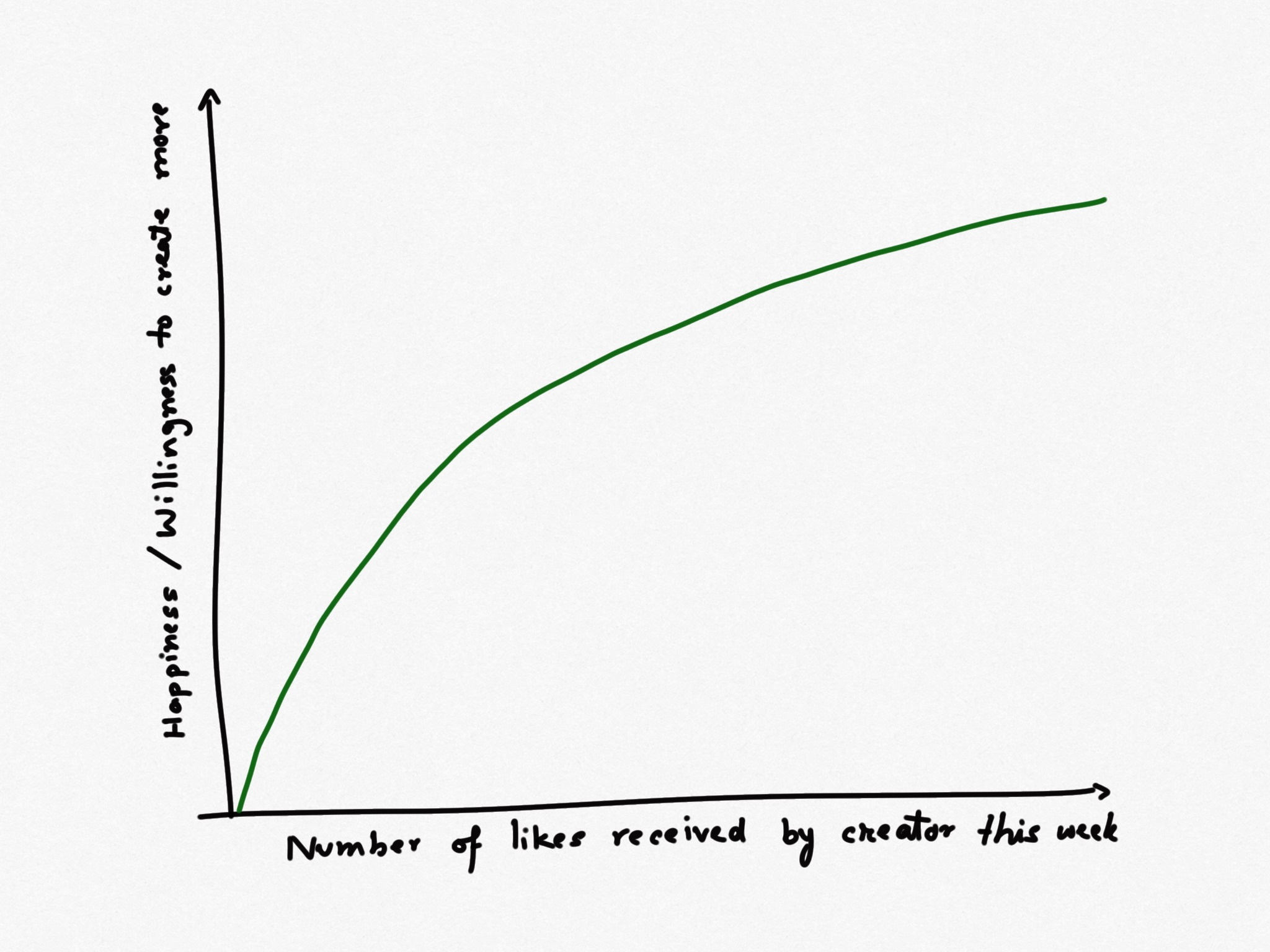
If our model of incremental happiness decreases with likes (see figure above), then a Value Model using Creator side Value will incentivize participation by more creators.
Value (item, user, creator) = UserValue(item, user) + CreatorValue(item, creator)
In addition to this there are a couple of other values to think of:
Ease of creation: How conducive is this item to spurring additional content creation?
For instance, on Tiktok, this would refer to how likely is the user to create a video from this. In case of Linkedin content creation could range in engagement from a like action to all the way creating a new post from it.Contribution to the platform: How much does this item help the platform in increasing their market share?
For instance, imagine a seller bringing a completely new item to an ecommerce market place. That will have benefits to the marketplace. It could increase the share of voice the marketplace has in this novel category. This value is known as diversity in recsys literature.
Conclusion
We talked about how traditional recommender systems favor content from established creators and why that is not enough.
For today’s content hungry digital platforms, we need recommender systems that encourage participation by a broad and diverse set of creators. This fairness is good for users, good for creators and good for the platform.
Disclaimer: These are my personal opinions only. Any assumptions, opinions stated here are mine and not representative of my current or any prior employer(s).
Wow! All your blogs are amazing... Thanks for writing all these blogs :)