Reducing selection bias / popularity bias in ranking
Through the post, code and videos we show how to make your multi-task ranking model unbiased


- Jointly with Ameya Raul author of Conformity-Aware Multi-task Ranking
Often recommender systems are trained using data collected by a recommender system. In this post we will show to account for a bias that creeps in due to this, that the data is over-influenced by power users and power items.
The approach that is commonly advocated is to factorize the signal you are getting from the user interaction into 4 parts:
the part explained by the position of the item
the part explained by the nature of the user, like a power / light user
the part explained by the nature of the item, like if there are biases against new and upcoming items.
the rest that cannot be explained by the above is hence new information that needs a more complex model arch which has access to both user and item features. (An example of this will be like me watching all of Minmin Chen’s talk (video), even though I am not a power user, or this video is not one with a lot of views.
Code & Video Walkthrough
Current state

Proposal 1 : Causal / Debiased ranking
We do this by two ideas:
Factorization / mutual information
Factorization: As explained in “Don’t recommend the obvious”, factorizing the observed label into the item-only probability and the incremental behavior of the user helps to
learn deep interests of the user (like my watching the Minmin Chen’s talk (video) will produce a strong positive gradient, since item-only effect is not much)
learn popular items that are not of interest to the user (like a user not interested in politics on a news app)
We also compute task probabilities (logits) purely based on user features to be able to distinguish between the importance of a label. For instance, a power user may consume a decent fraction of the items shown to them, but a user who rarely visits might engage with very few. Hence the signal of a power user engaging with an item should be weaker than the signal from an infrequency user.

Proposal 2: Anchored causal ranking
The only change we make here from proposal 1 is to add independent loss terms to the position, user and item logits. This helps in providing direct gradient to them and they are trained in a matter that is almost unaffected by other features. For instance, ui_logits is thus trained to model the residual after taking out the part already explained by the user and item.

Related ideas
In long-tail learning via logit-adjustment authors explain different approaches to remove a dominant effect and shine more light on marginal classes. We use this idea above for marginal users and less popular (perhaps newer) items.
A commonly used approach in ads / intervention modeling is one of uplift / advantage modeling. The way they do this is Expected [Utility] / P(Conversion) if the user u was shown ad x - P(conversion) of the user without showing the ad. One way to model the counterfactual is similar the user only logits we have computed above.
Appendix
In this article,
expands on some of the factorization ideas covered above.
Inspiration
These are some papers/resources I have read on this.
Disentangling User Interest and Conformity for Recommendation with Causal Embedding

As shown above they learn different representations optimized for “interest” and “conformity” loss and then concatenate it. In our proposed approach we have not used this approach. If you want to try this, could replicate a user label say clicked with two others (i) “clicked & item is popular” for conformity loss (ii) “clicked & item is not popular” for interest loss.
Conformity-Aware Multi-Task Ranking

The authors learn an embedding for conformity and relevance losses and use the relevance embedding in the regular multi task estimator.
Long-tail learning via logit-adjustment

This paper is written in a multi-class classification context where some classes are much rarer than others. The authors show that removing the logit of the class by itself from the gradient helps in learning a balanced and fair model. Otherwise models tend to overindex towards dominant classes. For instance if you have an imbalanced dataset with 2 classes with prevalence 99% and 1% respectively, you will get a very high accuracy by focusing on the dominant class.
While this could have applications in multi-task recommender systems with imbalanced tasks, this also works in causal debiased ranking. In fact the proposed approach above could be considered deducting the item only logit from the gradient from the label.Model-agnostic counterfactual reasoning for eliminating popularity bias
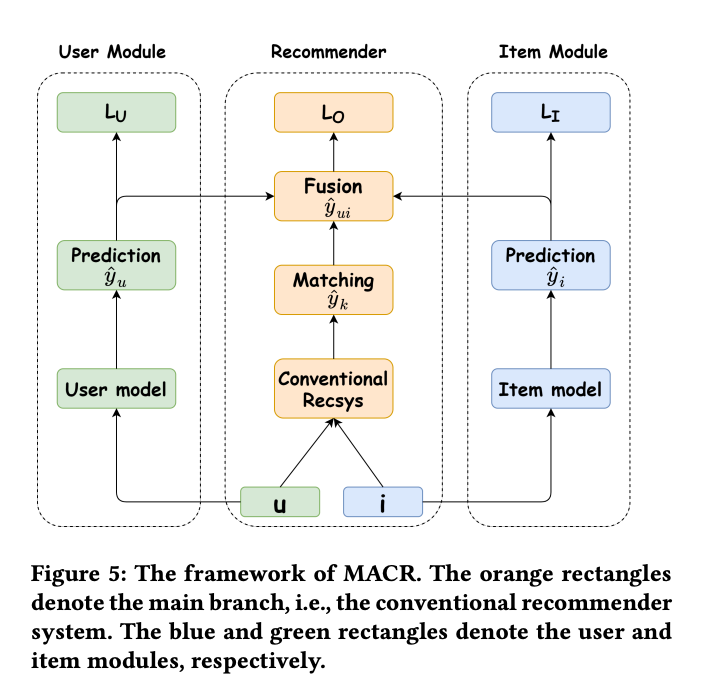
Similar to logit adjustment, except in the prediction (not logit) space.

The final prediction is a product of user-item logit and user-only probability and item-only probability.




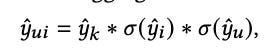
Disclaimer: These are the personal opinions of the author(s). Any assumptions, opinions stated here are theirs and not representative of their current or any prior employer(s). Apart from publicly available information, any other information here is not claimed to refer to any company including ones the author(s) may have worked in or been associated with.
 | A guest post by
|