User representation in a recommender system | memorization vs generalization
We look at memorization, generalization and mixture of representations based implementations for user preference representation in a recommender system



Representing the preferences of the user is crucial to personalizing recommender systems. In this article, we propose an approach to representing user preferences that we believe is optimal for large scale recommender systems. The approach is inspired by how humans communicate with others. We use progressively more memory when there is more historical context to fall back to (see figure below).

Similarly the approach presented in the section “Mixture of representations” uses table lookup based memory primarily for users for whom we have enough data to specialize, else it relies on a generalized representation.
Introduction: Generalization vs Memorization
We have seen successful recsys implemented using both schools of thought:
Generalization: Let’s not have any user specific memorization and purely personalize based on user features. Look at this seminal Youtube paper for an example.
Memorization: Let’s have a large lookup table keyed by user id. This is essentially a way to capture clear causality based specifically on the user’s preference. One could think of this as a modern recommender system incarnation of collaborative filtering, which even today is quote close to SOTA (see here). For those who want to learn collaborative filtering from the best, I recommend reading this chapter.
Outline
In this post, we will discuss various implementations to capture user preference:
table lookup
deep hash embeddings
generalization based on user cohort and not specific to the user
mixture of representations
We encourage you to try multiple approaches since the results could vary based on the scale, the dynamism of user preferences and how asymmetric the distribution of power / marginal user is on your platform.
Code
We share PyTorch code here. It is tested and freely available. We have also posted a walkthrough of the code on Youtube. See the first of the 6 videos below.
Memorization based user representation (Table lookup)
In this implementation, we create a (large) embedding table keyed with user id. Notwithstanding hash collisions, this enables us to memorize the user’s preferences and use it in future recommendations.

Deep Hash Embeddings
This is based on this seemingly magical paper, which achieves performance similar to id lookup without using embedding tables.
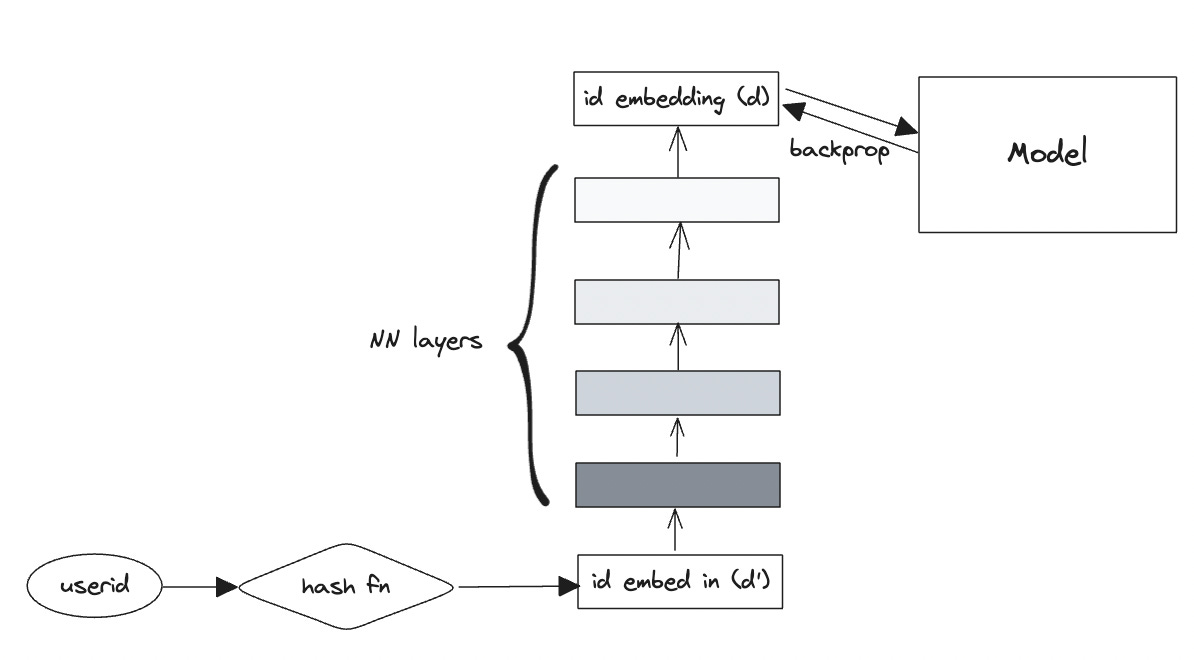
I believe the intuition is that the stacked neural network layers learn a form of generalization that is competitive with memorization with an order of magnitude less parameters.
User cohort / cluster based representation
In this implementation we only look at user features (not including user id). We have a embedding table of a smallish size, say 1024 and we try to find the index in this table the user should map to based on their features, like say location, broad interests etc. This is especially useful when you have very little information for this user.

Mixture of representations
Now we try to combine these ideas. In the image below,
the ”Table Lookup” refers to the module in “Memorization based user representation (Table lookup)” section.
the “Cohort lookup” refers to the module in “User cohort / cluster based representation” section.
Then we take a weighted sum. This weight is hopefully intelligent and knows how to use the best embedding for this user.

A note about sequential recommendation
Please note that this article is about understanding the user’s preferences beyond current session’s ephemeral interests. Sequential recommendation modules might be best at capturing those and making your recsys responsive. User representation and sequential recommendation modules should be complementary.
Disclaimer: These are the personal opinions of the author(s). Any assumptions, opinions stated here are theirs and not representative of their current or any prior employer(s). Apart from publicly available information, any other information here is not claimed to refer to any company including ones the author(s) may have worked in or been associated with.
 | A guest post by
|
 | A guest post by
|