Attention Explained: When to use Self, Graph, and Target-Aware Attention
Unlocking the Power of AI: A Beginner's Guide to Attention Architectures


TL;DR:
Self-attention summarizes information from a list (e.g., recent videos watched or chatbot text) to create a relevant summary.
Graph attention understands relationships within a network (e.g., social circles in a social network).
Target-aware attention evaluates the relevance of items being ranked to a user's history or query.
Attention is a powerful tool in AI, but its applications and types can be confusing. In this article, we'll break down three common attention architectures - self-attention, graph attention, and target-aware attention - and explore their use cases and strengths.
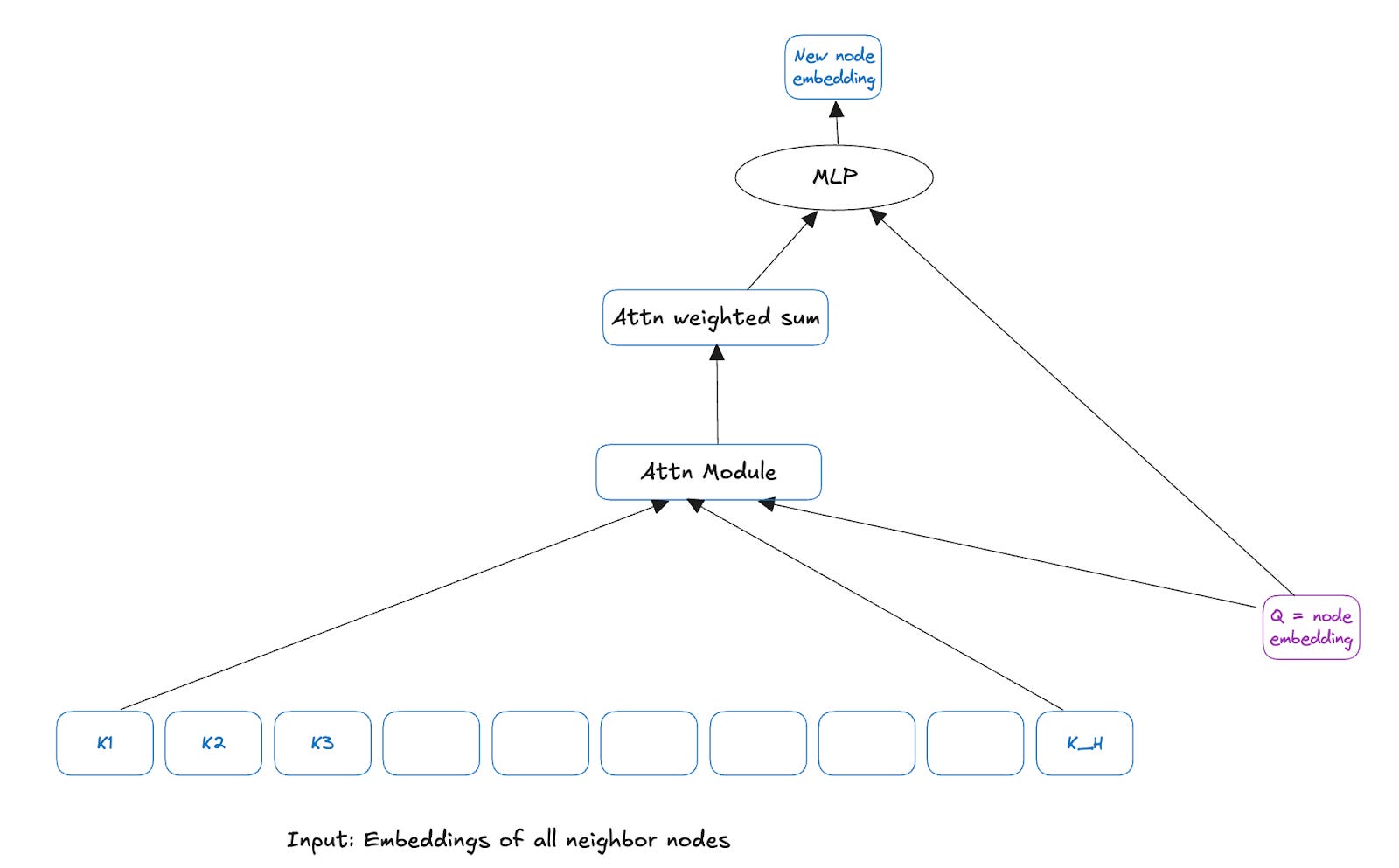
Basic building block of attention
The unit shown below in Fig 1, finds a weighted sum of the input sequence (aka “keys”) using the query embedding. One way to think about it is to find a summary in the keys that is most relevant to the query.
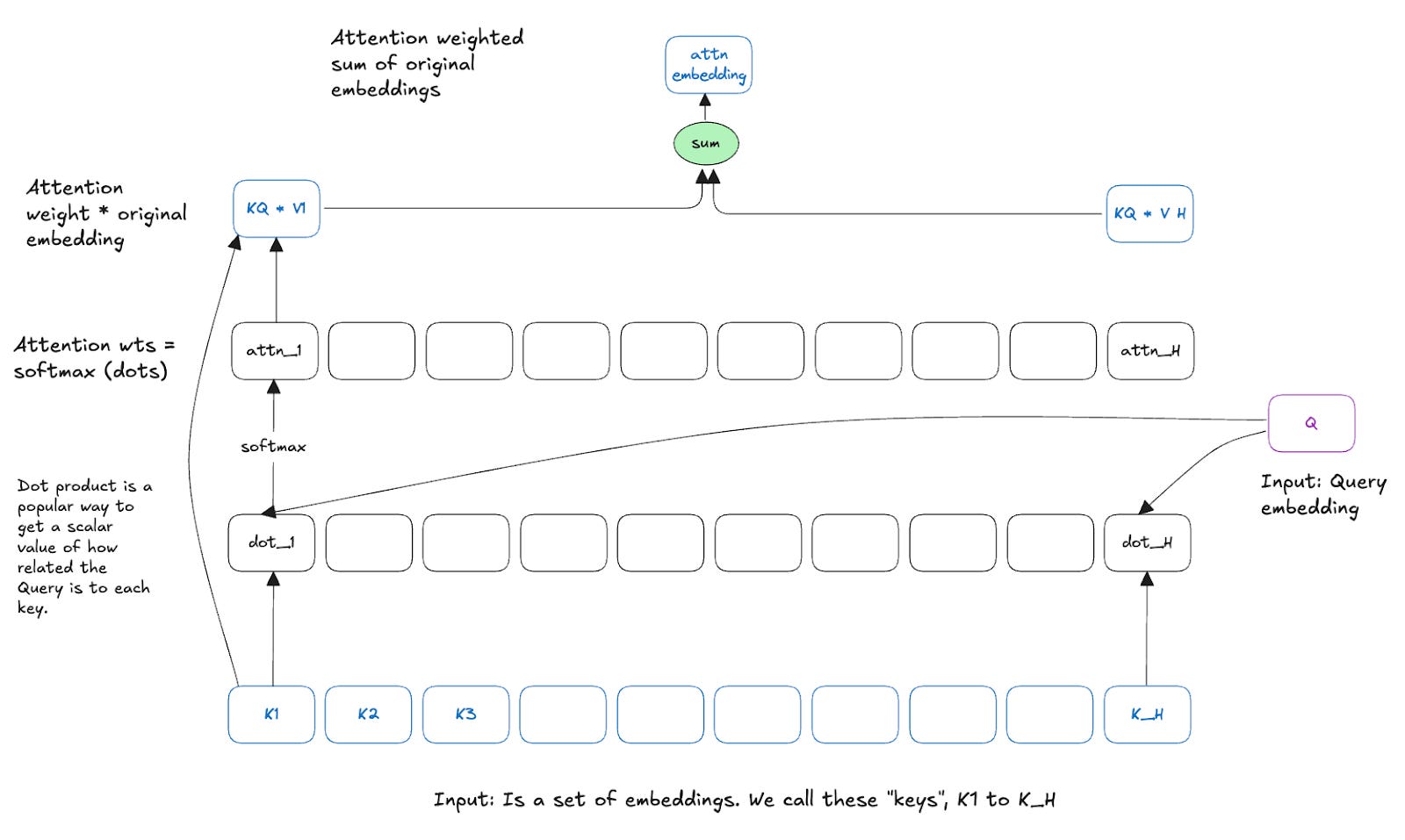
Self attention
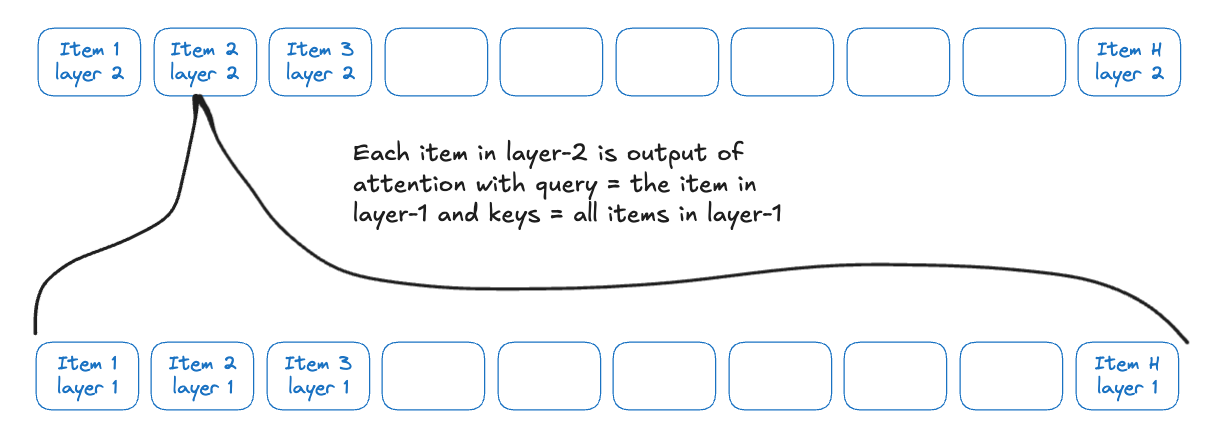
In self attention we generate an equal number of embeddings as the input. We do that by taking each of the inputs as a query. So post a layer of attention, each item in the list is replaced by a sort of smoothened version of it. (Fig 2)
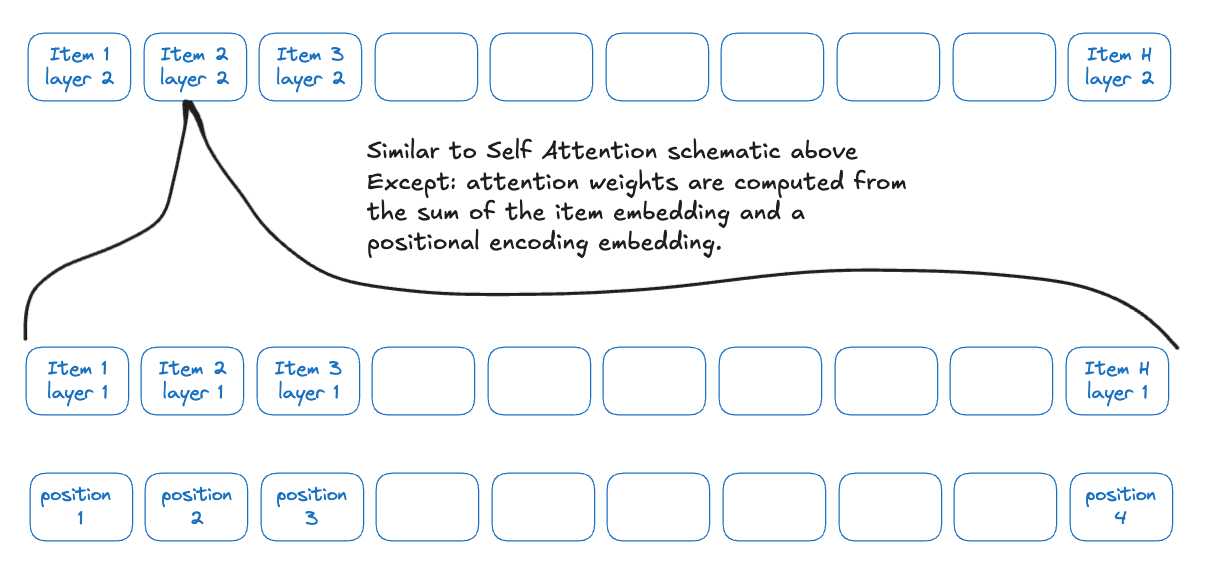
In certain scenarios like language and content recommender systems, where positions matter to the relevance of different items, positional encoding is also useful to find better attention weights. (Fig 3)
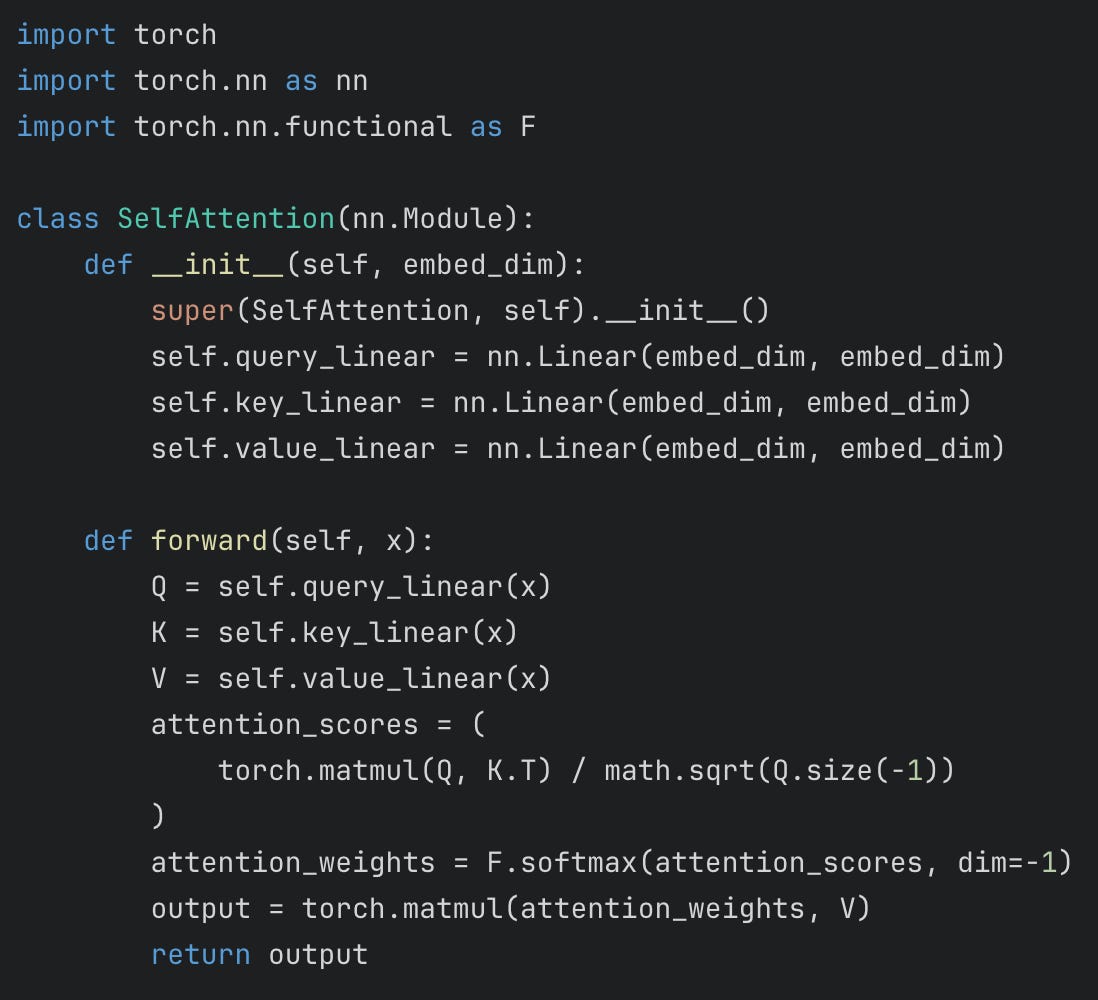
Code implementation
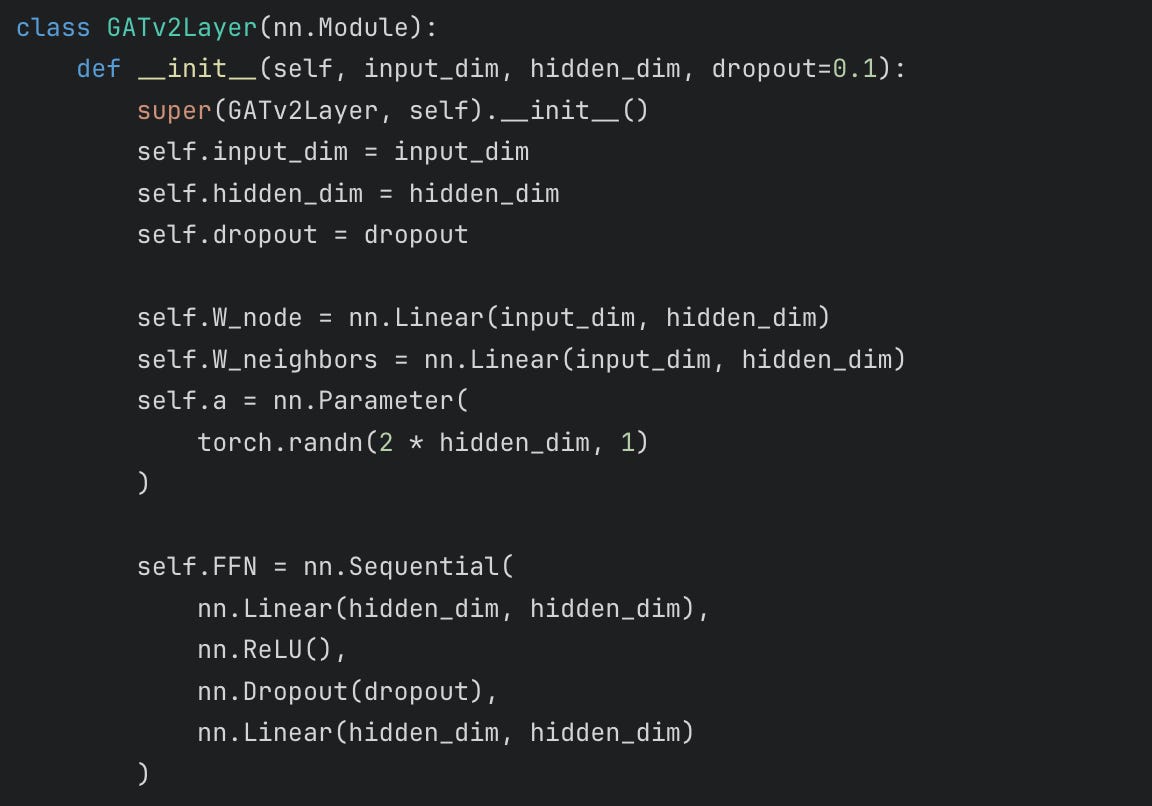
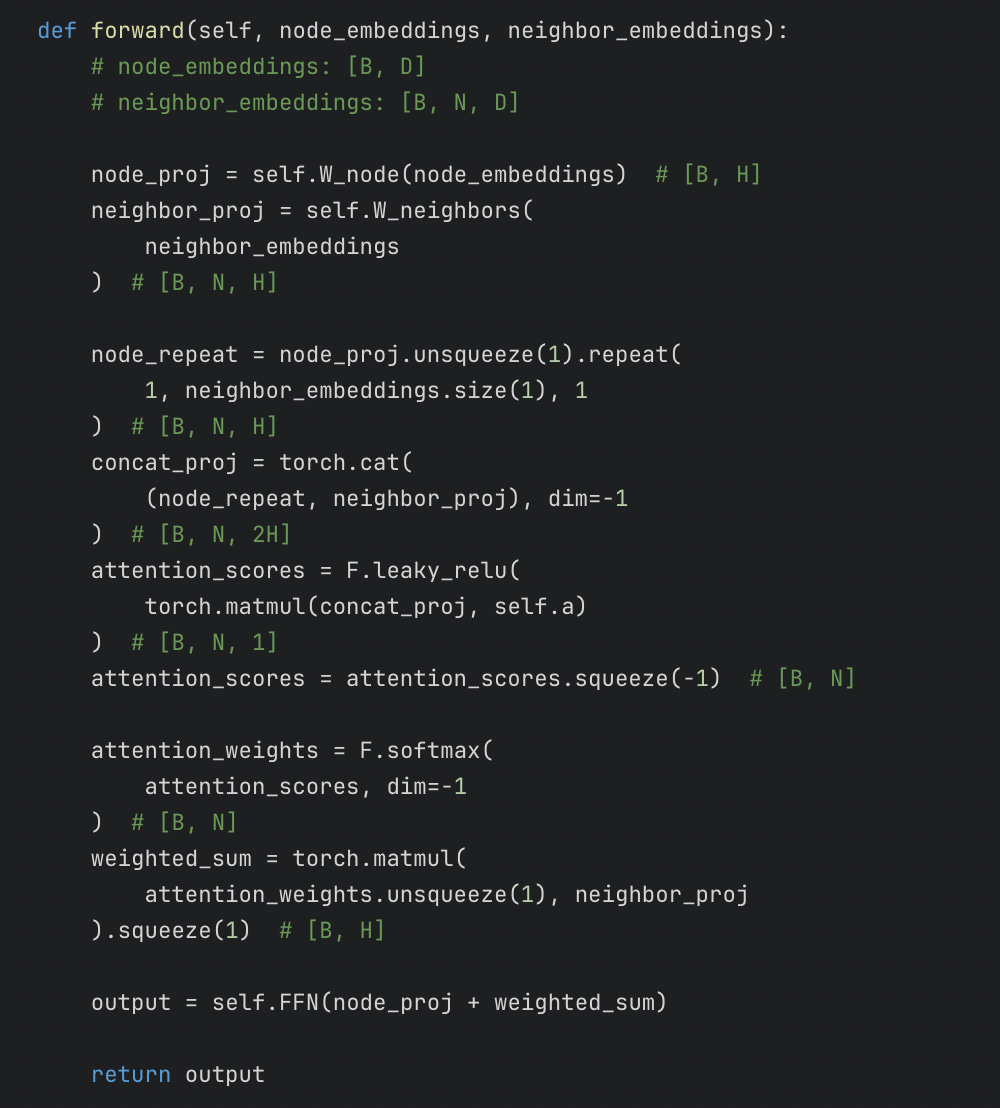
Graph Attention
Graph Attention is similar to Fig 2. As in, in each layer of attention, the embeddings of a node are updated using embeddings of items of the neighbors and their own. However the formulation is slightly different. Graph Attention Transformers decelerate over-smoothing by giving the node’s previous value as an input to the next layer neural network.
Code implementation
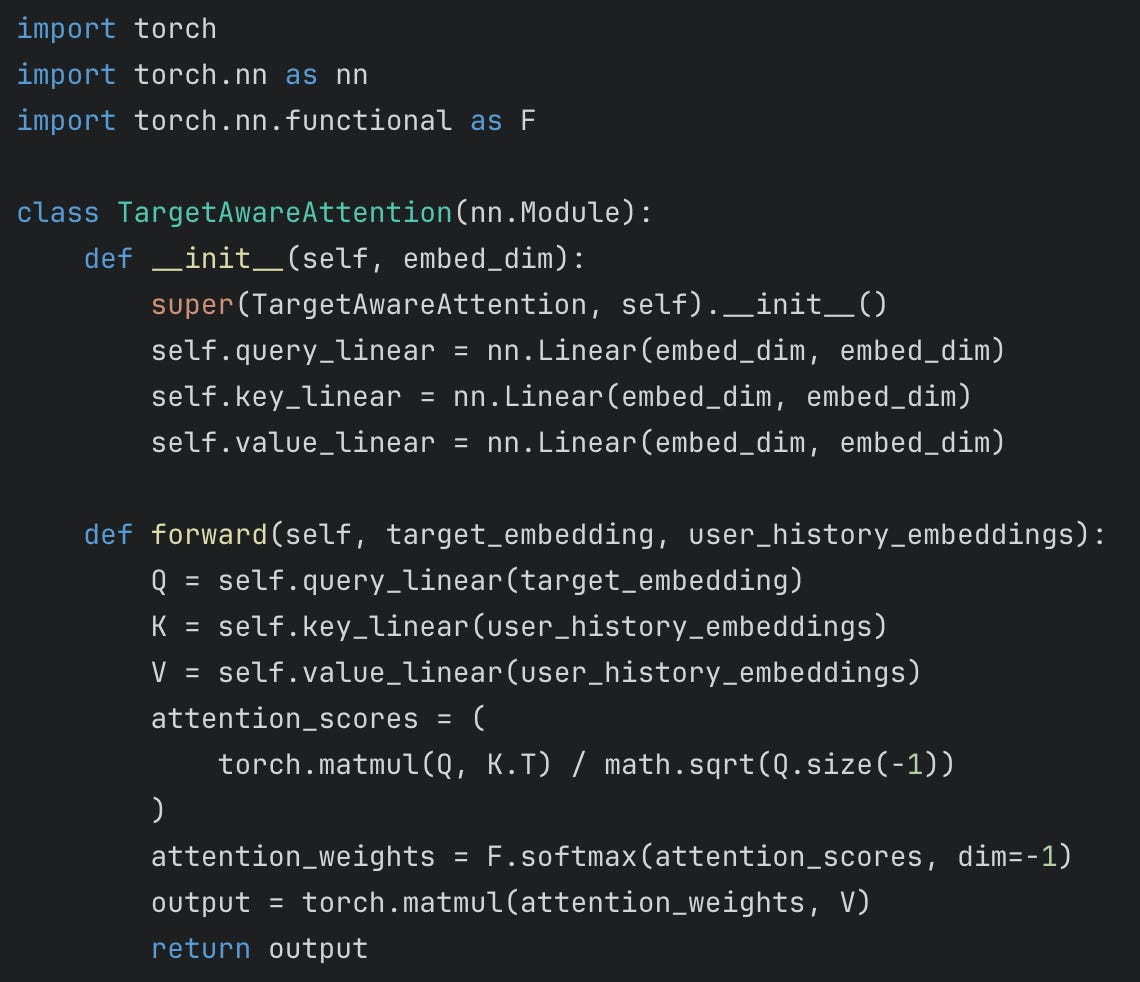
Target-aware attention
In ranking applications, we try to evaluate the probability of successful outcome with a number of options, aka “targets”. A successful application of attention in ranking stems from using attention with the target as the query and user’s history or query text sequence as keys.
In contrast to self-attention, target-aware attention uses a specific target as the query to compute attention weights over a sequence of items.
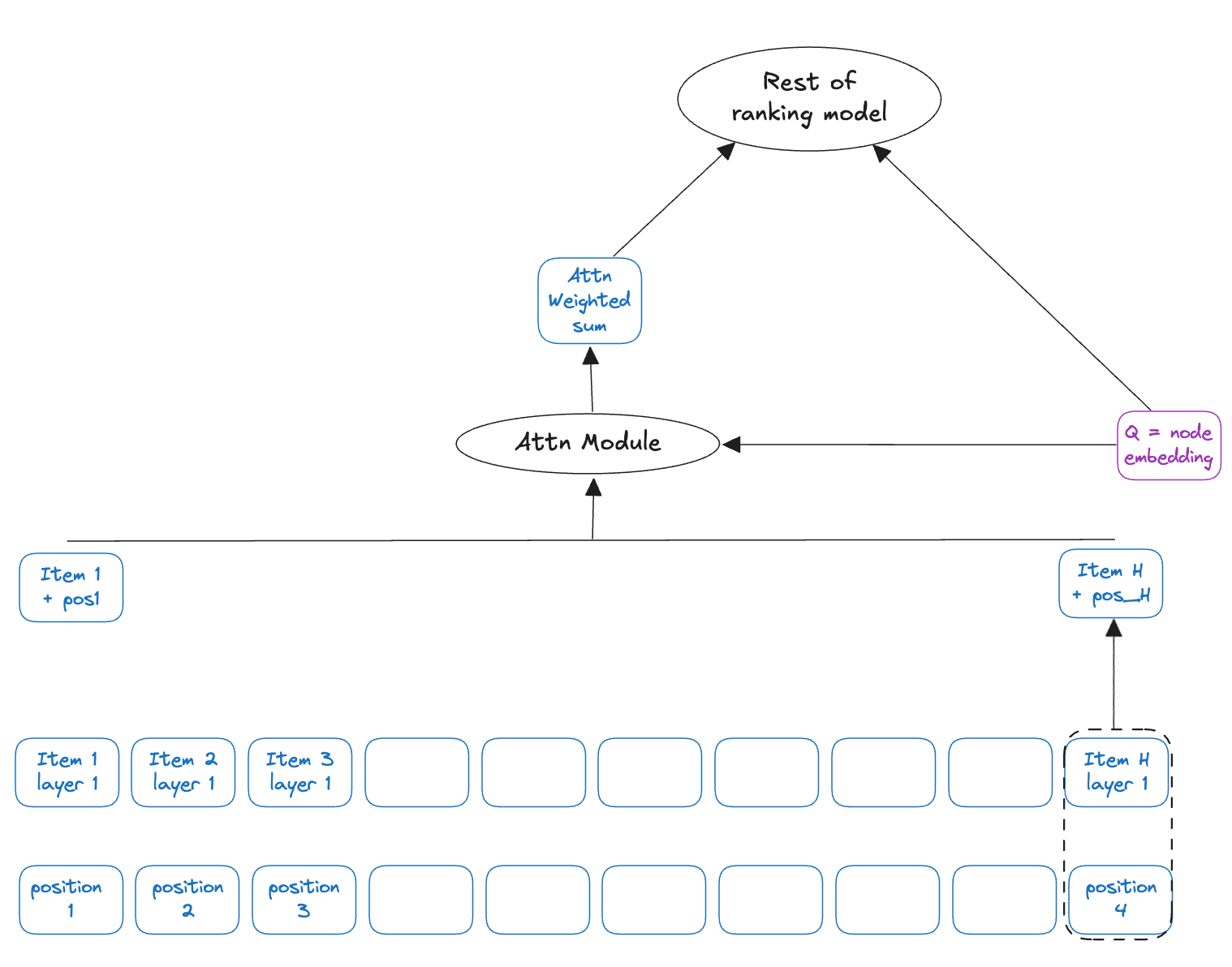
Code implementation
Conclusion
Whether it's processing sequences with self-attention, modeling relationships with graph attention, or ranking items with target-aware attention, each mechanism offers unique strengths. Use what is most applicable or a combination as needed. If you want to talk about your use case and what might fit the best, please reach out to us.
Prior posts on recsys stacks that can use attention:
Two tower models for retrieval of recommendations

The first tech stack you should build today for personalized recommendations is retrieval using two tower models[1, 2] and ranking on top of it. In this article we will learn about two-tower models and ranking will be covered in a future post. Using two tower models has helped leading tech companies improve the quality of their recommendations, online a…

Disclaimer: These are the personal opinions of the author(s). Any assumptions, opinions stated here are theirs and not representative of their current or any prior employer(s). Apart from publicly available information, any other information here is not claimed to refer to any company including ones the author(s) may have worked in or been associated with.
 | A guest post by
|