How to reduce cost of ranking by knowledge distillation
Using knowledge distillation can make your early ranking model more aligned with final ranker + Sample Code + Video walkthrough

There is an eagerness in industry to apply AI but the costs can quickly become prohibitive. In this post, we will show to apply ML in a cost effective manner in the domain of ranking.
We have been setting the stage for this in the previous two posts “What is an Early Ranker” and “System design of an Early Ranker”. To recap, an early ranker is used to filter down from say 2,000 candidates to about 200 which are then ranked by the compute-intensive final ranker. The early ranker uses typically about 5% compute cost per item compared to the final ranker.
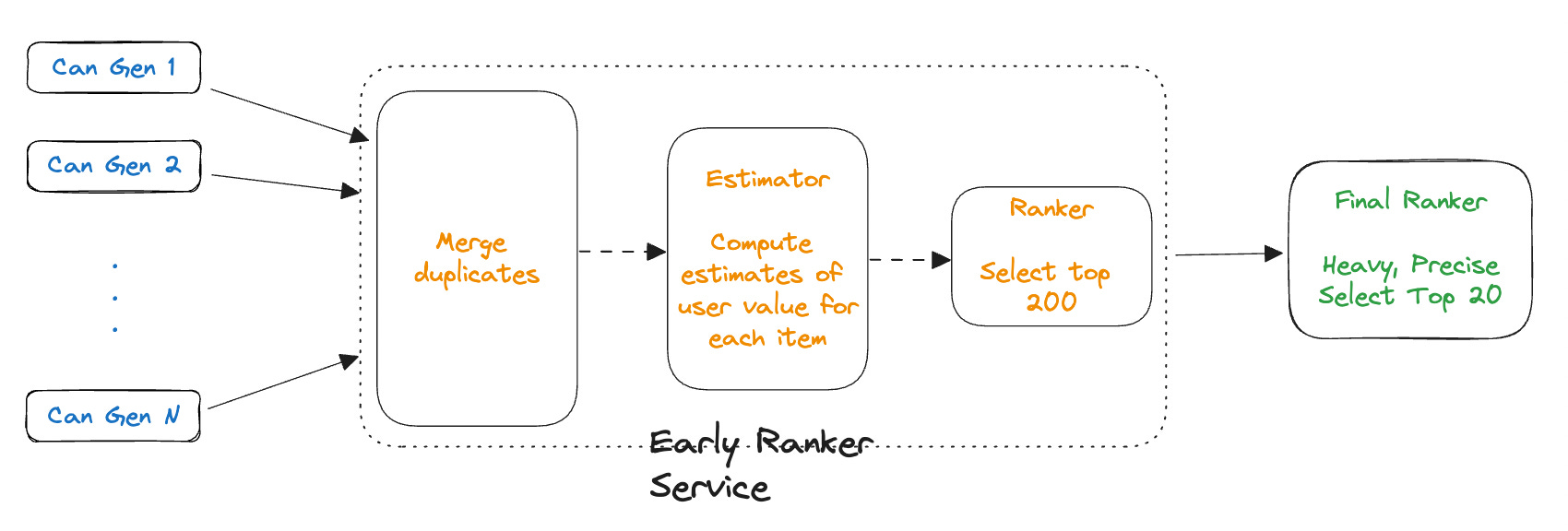
In this post we will talk about how to train an early ranker to be a good approximation of the final ranker. This will help because
It will improve topline metrics since items selected by Early Ranker will not be filtered by Final Ranker.
It can further reduce costs if you tune down the number of items selected from Early Ranker.
Sample code
PTAL original GitHub code here
Key idea: Teach Early Ranker to learn from Final Ranker (not just user actions)
Goodness of an early ranker is how good a proxy it is for the final ranker. A common way to describe this in Machine Learning is Knowledge Distillation, where a student model is trained to learn from a teacher model.
By “teacher model” we are referring to the final ranker. This is a high accuracy model but costly to run for too many items.
By “student model” we are referring to the early ranker.
The key idea here is that when you are evaluating (and also training) an early ranker, don’t just evaluate based on accuracy of predicting user actions on the recommendations but also on how closely its predictions match the teacher.
Current state: Early and Final Ranker are both trained from user actions
Usually we train the early ranker with the same inputs and training data as the final ranker, which is to emulate users’ actions.
For instance labels in a video recommendation feed would be like:
Did the user watch the video
Did the user like the video
Did the user share the video, etc
These are binary labels and hence you can use binary cross entropy loss to train the models.

Problem : Alignment
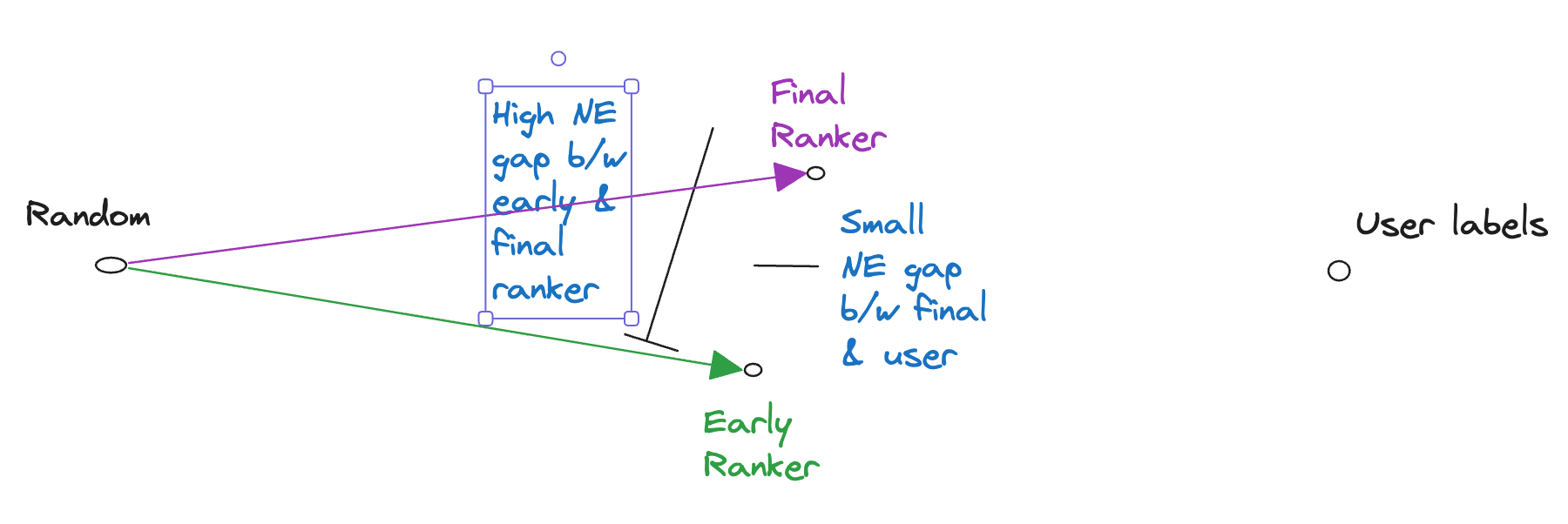
As illustrated in the image above, for a well trained system you might observe an alignment problem. i.e. You might observe is that the difference between cross entropy(user labels, final ranker) and cross entropy(user labels, early ranker) might be less than 1/4 times the cross entropy(final ranker, early ranker).
The early ranker learns to predict user actions well but not the final ranker. Hence many candidates it picks out are rejected by the final ranker.
Solution: “Knowledge distillation” to train Early Ranker from Final Ranker

The student model should be trained to stay close to the teacher model’s predictions.
For this you will need to:
log the final ranker scores alongside features for each item the user was recommended. See this article to understand why and how to set up feature logging alongside every recommendation.
add training labels to check closeness of the student’s model with teachers.
labels like
teacher_probability_watch
teacher_probability_like
teacher_probability_share
training data point weights to ensure that we only consider training examples where the probabilities were logged properly.
Hence offline metrics for training student model should include:
binary cross entropy against user labels (e.g. watch, like, share)
binary cross entropy against teacher labels (e.g. teacher_probability_watch, teacher_probability_like, teacher_probability_share)
Shared tasks vs Auxiliary tasks
You should try two approaches to knowledge distillation from final ranker to early ranker.
[Aux] Using teacher labels as auxiliary tasks

Pros of Aux approach:
Since the task predictions are separate, there is a little more safety in this approach in case something is messed up in the teacher logits.
[Shared] Using the same task estimate for both user and teacher label

Pros of shared approach
This will lead to a higher alignment
There is no increase in compute cost since the number of task heads have not increased.
References
For a more in-depth treatment of knowledge distillation, please read “Knowledge Distillation in Recommendation Systems” by Rahul.
Disclaimer: These are the personal opinions of the author(s). Any assumptions, opinions stated here are theirs and not representative of their current or any prior employer(s). Apart from publicly available information, any other information here is not claimed to refer to any company including ones the author(s) may have worked in or been associated with.