Scalable Embedding based retrieval for target side value
Addressing Scalability Challenges in Two-Sided Embedding based Recommendations


Friending recommendations in a social network have been known to deliver value by both finding targets that drive viewers to visit the app (“viewer visitation”) and initiating connections from viewers that lead targets to visit the app (“target visitation”).
In the post friend recommendation retrieval in a social network we have also covered embedding based retrieval. In this post we will focus on scalability and target side value.
Scalability
As noted in the previous post one of the most challenging aspects of embedding based retrieval is scalability since the query and candidate sets are 5Billion+ for large social networks.
Key insight: The retention value of people/friending recommendations is highest for users who are still building meaningful connections, i.e. “graph builders”.
We will use this below to engineer a low capacity high ROI retrieval system.
Target side value
Traditionally you will see two tower models only talk about viewer → best recommendations because many of these were written to maximize viewer value. You will see a diagram like below:
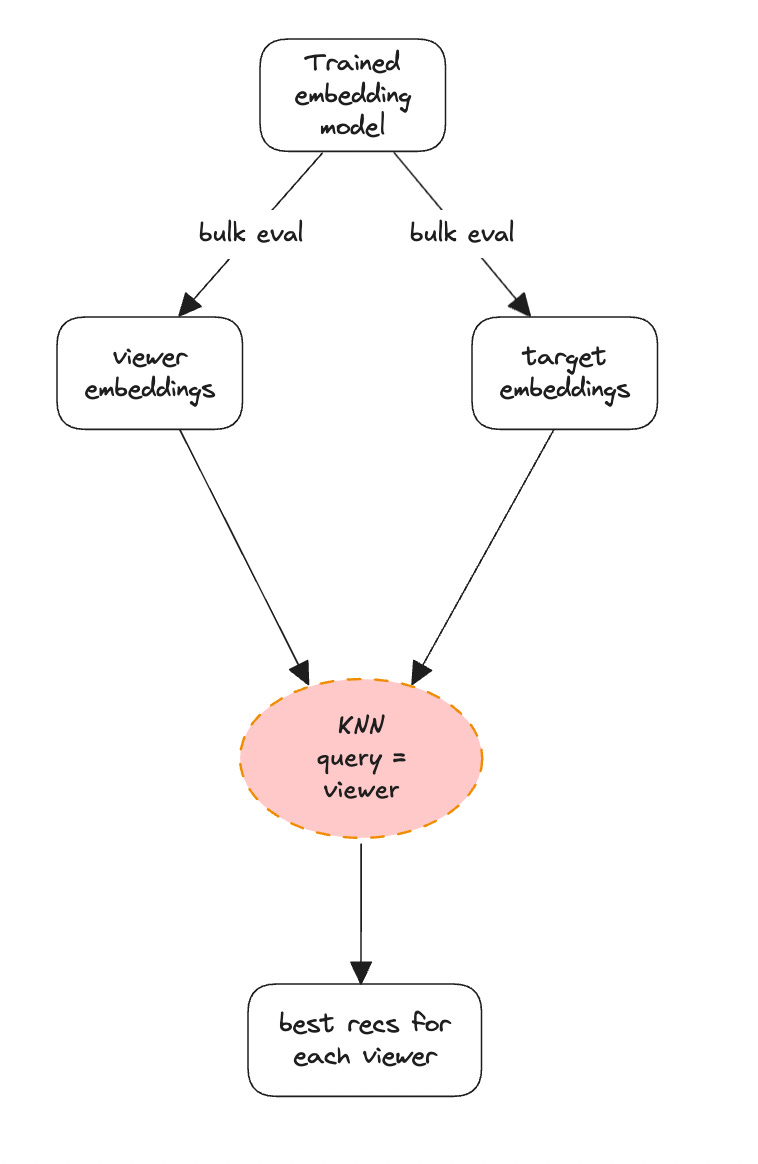
Even when accounting for candidate side value like the multi-stage system in short-video, the goal is to handle uncertainty of newer candidates. It is not to deliver value to candidates at the same level of importance as viewers.
If targets are as important, one option is to run a similar query with each target …

… and flip to add the targets to recommended lists for each viewer.

By now we have the basic argument in place. What is missing is scalability. It is not easy within the capacity, latency and time budget of modern social networks to run 5B+ KNN queries with 5B+ candidates. What we could do is to find the cohort we want to focus on and run the KNNs for only the cohorts most in need of good recommendations.

Algorithm: Maximizing target participation.
One part of this that we hand waved over above is how to “flip” the list of tgt → [list of recommended viewers] to viewer → list of targets.
A naive solution would be to just do it in Presto, etc., but what potential problems could arise with this approach?
Viewer flooding: Some viewers are recommended too many graph-building targets. This might degrade their experience and cause recommendation blindness (similar to ad blindness).
Target-starvation: Some targets might receive low “attention” since they are only in lists of viewers with too many graph-building targets.
This is a variant of the “Set-Cover” problem which is NP-complete. However, we will show below what is a decent approximation under large numbers.
Solution: Let’s say your target-side KNN produces a table named tgt_to_top_ten_viewers_knn_table, which has “target_id” and “viewers”, an array of viewer_ids. We can use the below algorithm to maximize the number of targets that are present in some viewer’s list and also get attention from them. The basic idea is to ensure that each viewer does not get more than (say) 3 graph-building targets.
-- Calculate the count of targets each viewer is associated with
WITH viewer_target_count AS (
SELECT
viewer_id,
COUNT(*) AS viewer_app_count
FROM (
-- Expand the tgt_to_top_ten_viewers_knn_table
-- into a table with target_id and viewer_id columns
SELECT
target_id,
viewer_id
FROM tgt_to_top_ten_viewers_knn_table
CROSS JOIN UNNEST(viewers) AS t(viewer_id)
) t
GROUP BY viewer_id
),
-- Expand the tgt_to_top_ten_viewers_knn_table
-- into a table with target_id and viewer_id columns
expanded_table AS (
SELECT
target_id,
viewer_id
FROM tgt_to_top_ten_viewers_knn_table
CROSS JOIN UNNEST(viewers) AS t(viewer_id)
),
-- Select targets for each viewer with a probability
-- that ensures each viewer is associated with
-- approximately 3 targets
selected_targets AS (
SELECT
et.target_id,
et.viewer_id,
vtc.viewer_app_count
FROM expanded_table et
JOIN viewer_target_count vtc ON et.viewer_id = vtc.viewer_id
WHERE RAND() < LEAST(1, 3.0 / vtc.viewer_app_count) -- Probability of selection decreases as viewer_app_count increases
)
-- Group the selected targets by viewer_id and
-- aggregate the target_ids
SELECT
viewer_id,
ARRAY_AGG(DISTINCT target_id) AS target_ids
FROM selected_targets
GROUP BY viewer_id;Conclusion
Model based retrieval is powerful in social network recommendations like Linkedin, Snap and Facebook. Noting that these recommendations deliver value to both viewers and the targets recommended can maximize retention for the app. In the article we propose approaches to deliver such viewer and target side value while handling scalability challenges of searching large sets of users.
We hope this spurs your imagination the next time you are thinking about building model based retrieval.
Disclaimer: These are the personal opinions of the author(s). Any assumptions, opinions stated here are theirs and not representative of their current or any prior employer(s). Apart from publicly available information, any other information here is not claimed to refer to any company including ones the author(s) may have worked in or been associated with.
 | A guest post by
|