How to prevent ML models from becoming stale
Applied ML #14

Raise your hand 🙋♀️ 🙋♂️ if you are an ads/search/recommendations ML engineer and if you have been a part of a launch 🚀 where the primary change was the retraining of the model on new (and possibly more) data. I have certainly been there, done that. In this article we will look at:
what leads to staleness of ranking systems and how to reduce it.
how to measure the performance of a modeling system and not a single model.
situations where the most recently computed model might not be optimal due to regime shifts.
Reasons why ML systems become stale fall under 3 broad categories:
A. Staleness due to delivery/cost optimization:
Client-side caching:
When the corpus size is small and recommendations are likely to stay the same between multiple visits, applications might cache recommendation results in the browser/app to reduce compute cost. (For e.g. recommended movies on Apple TV or recommended friends on Facebook)Server side caching:
Another approach to reduce computation costs might be to cache the recommendation results in a low-latency, low-cost in-memory cache, keyed by the userid. Applications might choose to use this a certain fraction of times and only apply a small ranking layer on top.Feeding stale dynamic item features
For instance the total video views, being used in the ranking model may not be fresh.
Fig 1.0: In case of dynamic content like short-form video recommendations, key features could be the number of likes, the estimated mean and variance of the like-rate / completion-rate per impression, and more fine grained mean and variance of like-rate / completion-rate per category. If the recommendation system uses values for these features that are are delayed by even tens of minutes that could lead to a significantly less popular platform!

B. Staleness due to modeling
Infrequent embedding computation:
Internally computed features like embeddings of items might be stale. These embeddings could be used both for retrieval and ranking.In-batch updating of embedding-search indexes1
Infrequent ranking model computation2
Manual launch process for all modeling changes:
Every time the embedding computation model or the ranking model changes, if one has to go through an A/B test and launch review then model launches will be delayed by weeks/months.
(See the example on high frequency trading below.)
C. Staleness due to new changes in the environment:
New anticipated events: like SuperBowl. Hence previous models and embeddings and user interests would lead to underperforming recs.
New concepts in the world3: like #brexit wasn’t a thing before it was!
Stale user interests in personalized ads/search/recommendation: while serving content, we could be missing recent user interactions.
A brief detour into high frequency trading (HFT) models
A lot of the operational problems being faced by the recommendation/ads/search teams have been faced and solved by the HFT community years ago. In an effort to being more cross-pollination of ideas, let’s look at how models are trained and retrained in the HFT space.
An HFT modeling config:
modeling_config {
feature_set // set of features to input to the ML model.
modeling_algo // the modeling algorithm and hyper parameters.
data_config // sampling config: the times of day the data is sampled from.
}We could train multiple models by rerunning this config with newer end-dates to product models like model_config1_20210518_20210618 is a model trained with above config from May-18-2021 to June-18-2021 and model_config1_20210718_20210818 is a model trained with above config from July-18-2021 to Aug-18-2021.
Stylized facts:
Newer models perform better on recent data. This is also true if we have tried to skip some recent dates from model construction to make them available to out of sample testing.
Model performance degrades steadily.
However, there are situations where there is a sudden change in market behavior and an old model trained on data that is very similar to the new market-regime is better than the model trained over the past month.
Challenges:
It is very hard to come up with unbiased data to test between two versions of the same modeling config. Let’s say we have trained a new model today (August-18), model_config1_20210718_20210818, we don’t have out of sample data to estimate its performance on.
If we wait for a few days to collect out of sample data to gain confidence in its performance, then finally when we get around to using this new model, it will already have become a bit stale.
Learnings:
Measure a modeling system and not a specific model.
Maintain a diversified set of models output by a config; Rank and pick based on the expected regime/context on the day.
Proposed Solutions
The following solutions are roughly in decreasing order of ROI:
Impression demotion: (low effort, high reward)
In case of client-side and server-side caching, demoting items previously seen by the user provides a fresher experience while still retaining caching.Using embeddings instead of hard-coded taxonomy of topics/categories: This handles concept drift better, especially if embeddings are updated frequently.
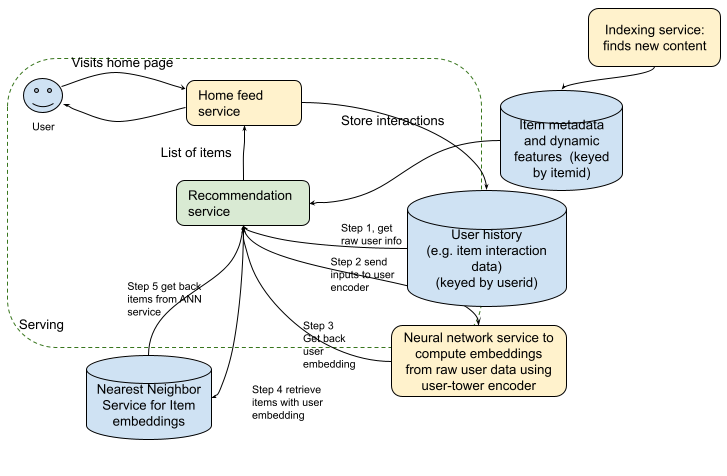
(medium effort, high reward)Use raw user history at serving time instead of precomputed user embeddings or processed user features.
(medium effort, high reward)
Fig 3.0: Instead of computing user embeddings in batch and storing them in a feature store, compute user embeddings at serving time. This will reduce the staleness of the user model. Another take on this without computing user embeddings is PinnerSage work by Pinterest team. They compute user embeddings at serving time by clustering the item embeddings of items the user has interacted with. This is more conducive to diversity boosting of recommendations since users might have different goals in past interactions and not just one.
Launch modeling systems and not individual models
(high effort, high reward)Make Launch decisions about modeling systems that include automation of when the models will be recomputed and deployed.
A/B tests: Both for offline metrics (performance of new version on previously collected data) and online metrics (performance of new version on a fraction of users in a live experiment), compare the old system vs the new system.
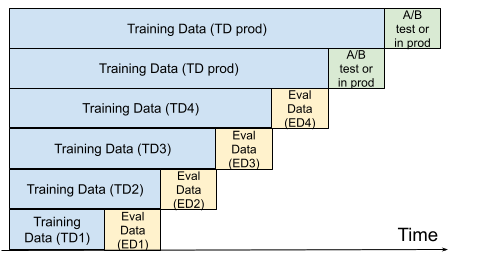
Walk-forward measurement:
While model training, instead of shuffling the data and evaluating on a random sample of the dataset,
Fig 3.1: Currently teams mostly use a randomly sampled subset of historical data fro training and testing, then run an online A/B test and then move the model to prod if successful. Unfortunately the model gets to see some data temporally after some dates of the eval data. Hence the metrics do not reflect real life usage. Also the model is somewhat stale by the time it reaches production. use the following:

Fig 3.2: The goodness/metric of the modeling config is computed as the sum of metrics over model on TD1 on ED1, model(TD2) on ED2, model(TD3) on ED3 and so on. The model that is used for A/B tests and production is the one that is most recently trained and not a stale model. or adhering to the same principle but using a fixed size training window

Fig 3.3: Similar to Fig 3.2, the performance metric is computed in historical data over a sum of metric values on eval data, each of which is only scored using a model that was trained on the corresponding training data. Similar to Fig 3.2, the model used in live experiments or in production is also freshly trained.
Use end-to-end item ranking models without any precomputed feature stores:
If the item encoder operates directly on raw data and not on precomputed features then you could avoid a further source of staleness, and reduce your ML-tech-debt significantly. This will also help to reduce the urge in your team to invest time in feature engineering, which quickly becomes low return-on-investment.
(high effort, high reward)Regime detection and pick model based on it
For the modeling config that is in production, we could choose to maintain a small set of models available to be served in live. Somewhat similar to the motivation of multi-head attention or Batch-Shaping for Learning Conditional Channel Gated Networks, the set of models are fine tuned to different regimes and complement each other. Based on data in production, build a system to shift the allocation between these models real-time.4
(medium effort, medium reward)


Conclusion
Staleness of results of an ML application is a major problem and one that leads to a user-visible poor experience. We have talked about a number of reasons for staleness. We looked at how the high frequency trading industry has tackled this issue. We have proposed solutions to address it for recommendations/ads/search.
Disclaimer: These are my personal opinions only. Any assumptions, opinions stated here are mine and not representative of my current or any prior employer(s).
Most recommendation systems start with a retrieval stage which needs one to search the nearest neighbors to a given embedding, or (MIPS) the items whose embeddings have the maximum inner product with the given embedding. Google’s ScaNN service for instance provides this service at multiple millions of queries per second. As shown here (Auto-Faiss), optimizing these embedding indexes leads to an order of magnitude better performance. Usually this entails optimizing the entire batch of embeddings together, and is usually done infrequently, whereas an item embedding could technically be updated real time with every user interaction.
Ranking Models might not have been retrained recently, for example neural network weights and decision tree parameters for ranking. This gets even more complicated when there are multiple stages of the models, like a neural network feeding into a decision tree and both models need to be updated together. (A good resource to understand how to solve this problem)
Extraction of concepts / entities from content might be missing current events. For instance, #Brexit became a thing on social media and news, and for a while the set of topics a recommendation system was trying to extract from a content item might have been missing that new topic.
Note that we have not proposed making a completely online modeling system, which is updating the model on every interaction. In some applications that might be unavoidable. However, in general we feel that incurs more cost than benefit. Regime based model allocation is a good proxy.