

LLMs and Recommender systems, like the ones used in video recommendation and friend recommendation, might seem very different to most but in this post we compare them to show they are surprisingly similar. We highlight one key opportunity for recsys community to improve. Under the surface they are a similar problem:
Given a context, choose the next action that maximizes value.
Action can be “Next token” for LLMs and “Next item/action” for RecSys.
1. Retrieval ≈ Pretraining+SFT. Ranking is missing Reward optimization.
LLMs are developed using
pretraining using next token prediction loss on a lot of data not specific to a domain.
fine tuned still using next token prediction loss but only on high quality data to improve for the domain, typically at smaller learning rates.
optimized using Reinforcement Learning to maximize expected reward (e.g. using Policy Gradient).

Retrieval in recsys is done by finding user and item embeddings to maximize the probability of next item interacted by the user. This post shows that Pretraining/SFT = Recsys Retrieval and how Semantic ID + clustering are blurring them even more.
2. Reward optimization in LLMs vs “Ranking” in RecSys
This is where the two worlds spiritually reconnect but architecturally diverge.
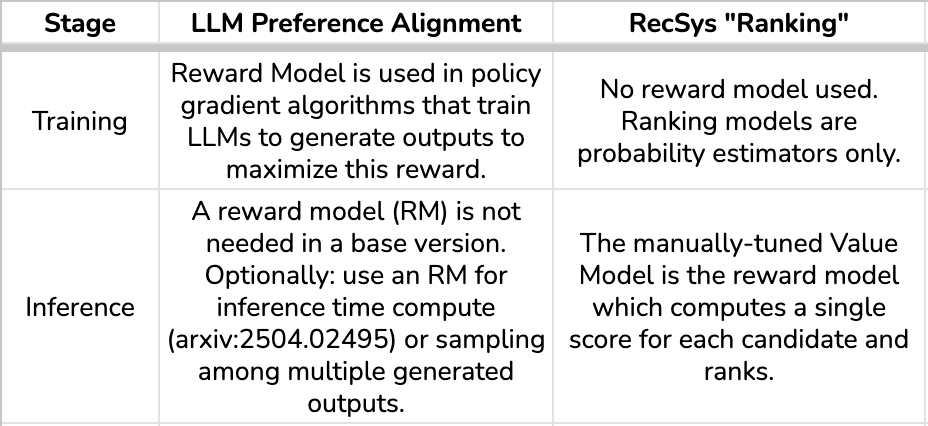
Note: RL-Aligned vs. Generative RecSys It is important to distinguish this proposal from “Generative Recommendation” (where an LLM directly generates Item IDs as tokens). What I am proposing here is an evolution of the training paradigm, not a replacement of the inference engine. We move from minimizing classification error to maximizing policy reward. It just changes the training loss without any degradation of inference latency or increase in inference cost.
3. LLM Alignment (RLHF etc) uses a reward model to maximize user value
Train a reward model that scores outputs.
Train the policy (the LLM) to maximize that reward using some form of policy gradient.
Use KL-regularization to keep the policy safe, stable, and within distribution.
The key point: LLMs actively optimize against a reward model.
Training learns to find parameters θ such that the probability of generating a token πθ(y|x) is highest for pairs (x, y) which will lead to highest reward under the reward model provided to it.
4. RecSys Ranking model is a probability estimator
See this post for a deep dive on Ranking models in recsys. “Ranking” models are, as of today, trained to predict a vector of probabilities like:
p(click)
p(engagement)
p(return next day)
On top of these predictions, engineers write a hand-coded value function, for example: Value/Reward = a * p(click)+ b * p(engage) + c * p(return next day)
This is a modular, transparent, and auditable solution that enables rapid, component-wise experimentation and deployment.
But critically:
RecSys ranking models do not optimize the value function.
They only predict the labels that go into it.
There is no policy gradient step. No RLHF stage.
No optimization w.r.t. actual business or user value.
This is a fundamental architectural gap.
And unlike LLMs, RecSys systems operate in a ~live feedback loop:
The policy (Ranking estimator + Value model) determines the user experience,
the experience determines user actions,
those actions populate the training data,
and the model is trained on that data again.
Yet RecSys systems still treat the “ranking” model as a static classifier rather than as a policy.
5. The Opportunity: RecSys Needs Its “RLHF Moment”
The RecSys world already has all the ingredients LLMs needed for RLHF:
a probability estimator (the ranking model)
a scalar value model (the downstream business/value estimator)
logged human preference data
a feedback loop
constraints on drift and safety (analogous to KL-regularization in LLMs)
But RecSys stops short of the final step:
Treating the ranking model as a policy and training it to maximize reward.
Imagine a RecSys training pipeline where:
The value model becomes the “reward model” (both inference reward model and training reward model).
The ranking model is updated to maximize this reward:
The value model score for each item is computed using task predictions. This is an invocation of the “inference reward model”
\(s_i = \sum\limits_{t=1}^{T}\text{vm}_t * p_{\theta, i}(\text{t})\)From this we compute the probability of this item being ranked first (Plackett-Luce model). ‘N’ refers to the number of items being ranked.
\(\pi_\theta(i|x)= \frac{e^{s_i}}{\sum\limits_{i=1}^{N} e^{s_j}}\)Optionally but recommended to compute the probability of the logging policy ranking this item first. You will need to log the probabilities estimated by that model for this. If you don’t have this then you can assume \pi-beta(i|x) = 1
Compute the inverse propensity estimate:
\(\rho_i = \frac{\pi_{\theta}(i|x)}{\pi_{\beta}(i|x)}\)Compute an “observed reward”. We can use the “value model” as this training reward model. For instance, this could be
\(r_i = \sum\limits_{t=1}^{T}\text{vm}_t * \text{user_action}_{i}(\text{t})\)Add an RL loss which when minimized helps us learn a ranking model that maximizes the reward.
\(\mathcal{L}_{\text{RL}}(i) = - \rho_i \cdot r_i\)Try improvements like GRPO (DeepSeekMath) / ECPO (OneRec) / GBPO (OneRec-V2) / CISPO(Minimax-M1) to improve the Off-Policy estimate of the reward. These will no doubt improve the variance of ‘ρ’.
Note: The only term in this loss that is affected by model parameters are the predictions, same as current ranking state. The gradient flows back through the probability estimator $p_\theta(t)$.
Why is this better?
The system optimizes the actual long-term metric end-to-end.
Training is paying more attention to instances that will actually deliver metrics instead of being more accurate in low ROI parts of the training data.
This will open up a lever for growth for your recsys, which is to improve the training reward model.
“Ranking” would finally become reward optimization.
6. Code implementation
7. Closing Thoughts
LLMs and RecSys systems share a deeper architectural similarity than most people realize.
Pretraining mirrors retrieval.
Policy sampling at inference mirrors top-K ranking.
Reward models mirror value models.
But LLMs have unlocked remarkable capabilities through policy-gradient-based preference optimization,
while RecSys still primarily relies on probability estimation + handcrafted value models.
The RecSys field is on the cusp of the same evolution.
The next major leap in recommender systems will come when ranking models shift from estimating probabilities to maximizing reward—just like modern LLMs.
We already have retrieval.
We already have value models.
We already have logged user preferences.
We already have constraints and safety layers.
All that’s missing is the optimization layer.
RecSys is ready for its RLHF moment.
Disclaimer: These are the personal opinions of the author(s). Any assumptions, opinions stated here are theirs and not representative of their current or any prior employer(s). Apart from publicly available information, any other information here is not claimed to refer to any company including ones the author(s) may have worked in or been associated with.

