

The intent of the post is to explain the ranking model in detail to tee up future posts explaining how this should change learning from LLM advances.
High level structure
Retrieval —> a relatively small set of candidates —> [ Ranking + Value Model ] —> Sorted order presented to the user.
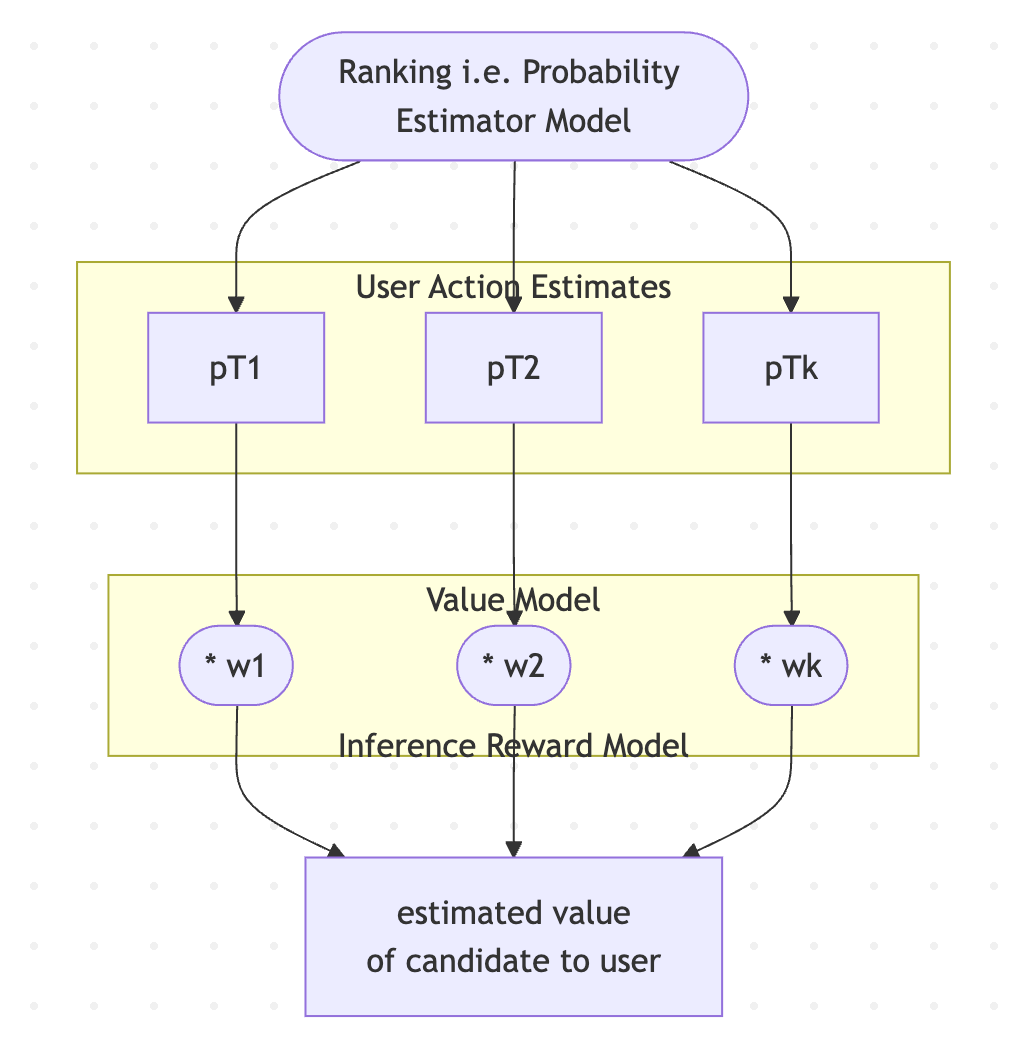
So “Ranking” = Estimator model + VM which:
compute estimates of probabilities of user actions / user experience labels on presenting this item
use a Value model to compute a weighted sum of these probabilities into a single score and rank with it.
Ranking model architecture
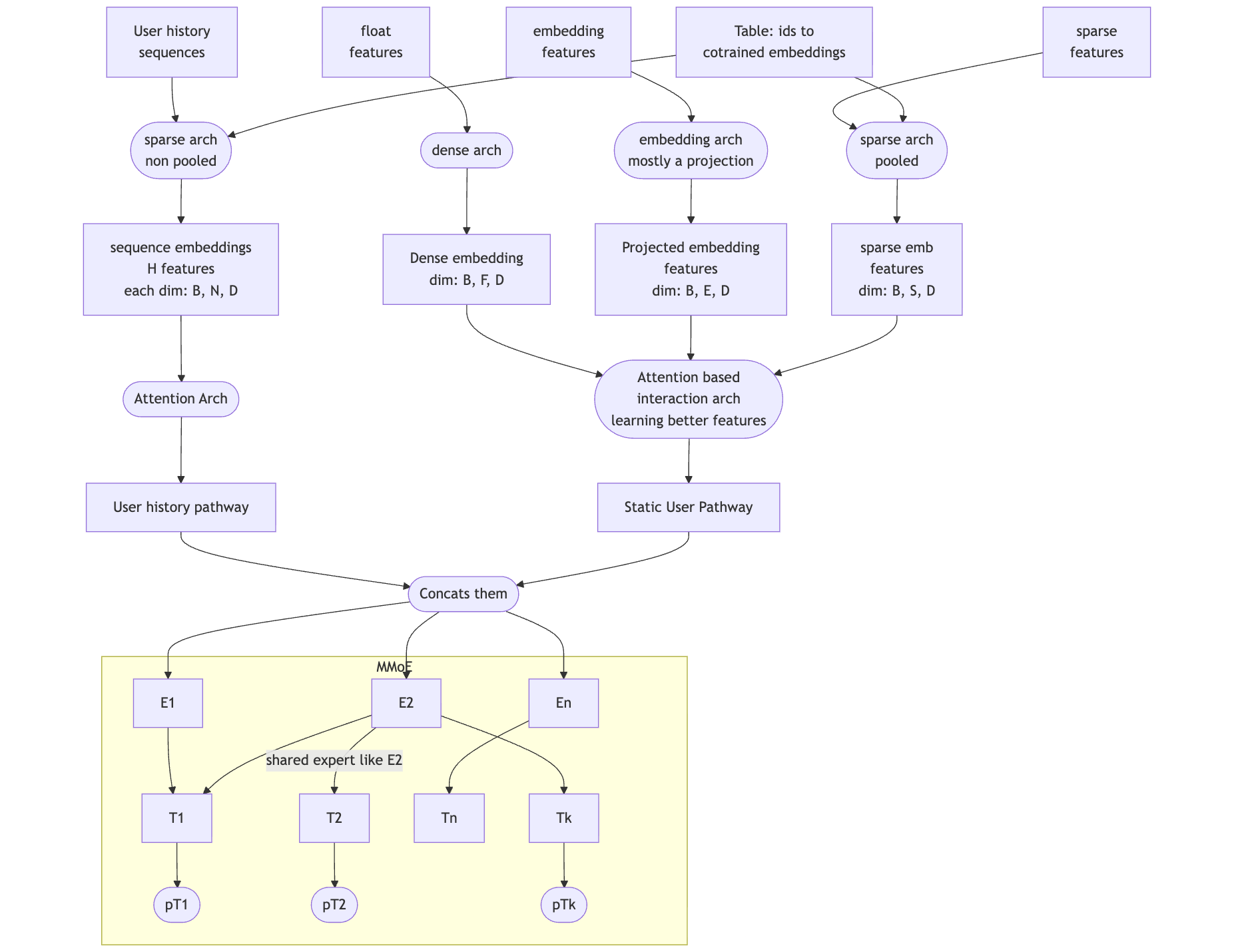
Explanation of terms:
“float features” are typically single values, like number of mutual friends between viewer and target in friend recommendations or cosine similarity between graph neural network embeddings of viewer and target. These are also sometimes called “dense features”.
“embedding features” are full embeddings, like 128 floating points of a 128 dimension graph neural network embedding. The reason these are not just treated as “float features” is because processing them in the model as the vector/tensor leads to better model accuracy.
“sparse features” can be either class-based features like category-id of a song in music recommendation or also lists of ids like “last N user ids messaged by the user” if they are summed up into a single embedding and not retained as a list.
“User history sequences” are typically lists of ids like “last N user ids messaged by the user” but the entire sequence is retained and available to the model.
The “Interaction Arch” can be thought of as processing the non sequence features into a “user static pathway” the borrow the term from OneRec Technical Report.
To read the dimensions in the image above, for example [B, E, D] refers to [batch size, number of embeddings, D is a fixed number that is shared by most embeddings similar to d_model in LLMs or OneRec.
Prior posts on ranking



Disclaimer: These are the personal opinions of the author(s). Any assumptions, opinions stated here are theirs and not representative of their current or any prior employer(s). Apart from publicly available information, any other information here is not claimed to refer to any company including ones the author(s) may have worked in or been associated with.
