Building Generative Friend Recommendations
OneRec has established a blueprint for Generative Video Recs. This post shows what to change for Generative Friend Recommendations

Main difference between recommending videos and recommending friends is that in friend-recs we are working with a 1000 times less positive signal and most of it delayed.
Out of the five parts of generative recs: (a) Semantic Embeddings (b) Tokenization (c) Modeling (d) Training Losses for modeling (e) Reward modeling1 illustrated in OneRec Technical Report, Semantic Embeddings and Training Losses are chiefly the ones that need to be changed when building generative recommendations to recommend friends like “people you may know”.
(Yes, this is a simplified view, but one to help you get to good enough MVP)
Outline: In the rest of the post:
We explain the seismic shift happening in recommender systems industry after OneRec paper and why.
A high level summary of OneRec
Which parts need to be changed for Generative Friend Recs and why
^ video explaining the post and presenting slides
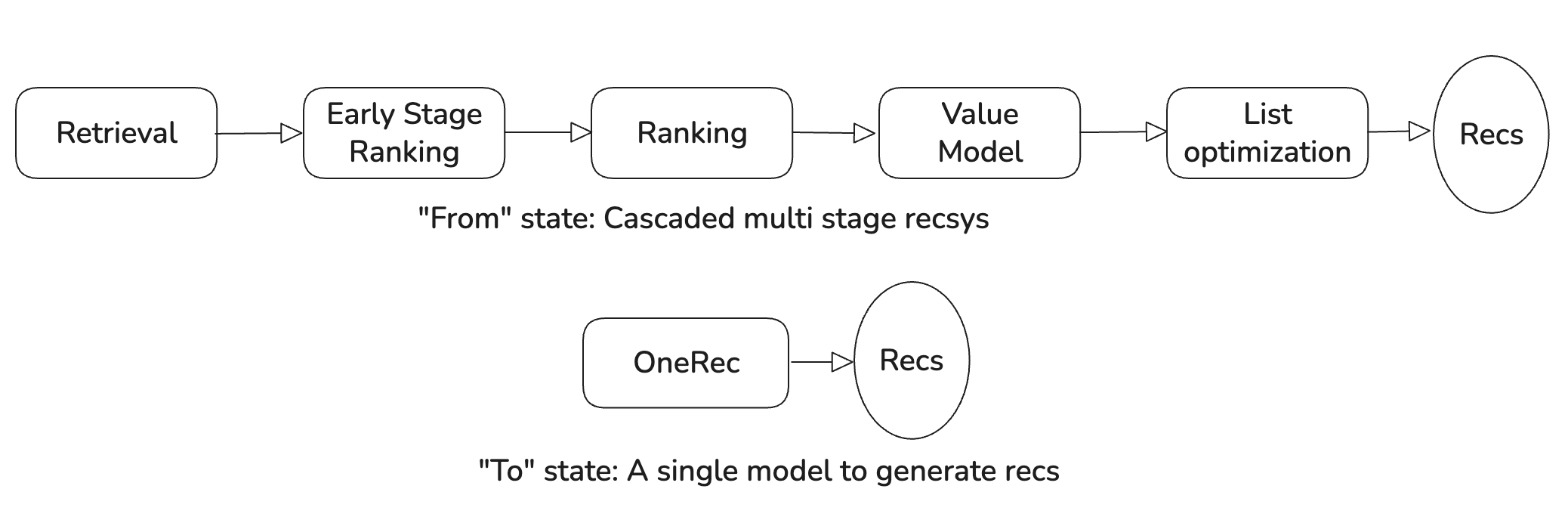
Generative recs is changing the world of recsys
OneRec achieves lower system complexity, better app stay time and lower organizational investment using generative recommendations.
To elaborate, Youtube’s TIGER paper demonstrated that if we can represent the videos to be recommended in under 100K tokens2, we can use LLM models to recommend. OneRec goes one step further and builds a reward model that enables them to replace the entire recommender and not just retrieval. Now they can retire their multi-stage recommender system and just use this LLM-like model end to end to directly output a list of recommendation items.3
Most bigtech recsys teams are making generative recommendations their big bet. Reasons:
OneRec changes recsys from the traditional multi-stage process to a single stage process which makes organizational investment much more streamlined. You don’t need separate retrieval, early stage ranking and final stage ranking and value modeling and list generation (aka post ranking) teams now if OneRec can do it all.
This makes the recommendation system amenable to be “driven” by product. Imagine you don’t want viral clickbaity videos. It would be a costly multi-team effort to do so earlier. But with OneRec specifying it in the reward works. Imagine you want the recommender system to drive more Daily Active Users instead of sessions (or app opens), you can do that by shaping the reward.
The single most effective ML strategy has been metaphorically to get on trains others have built for you and to ride it close to your destination. The LLM world is building a train, with optimized kernels and infrastructure. If recsys can ride it then it can unlock a step change, as demonstrated by OneRec’s results.
High level summary of OneRec
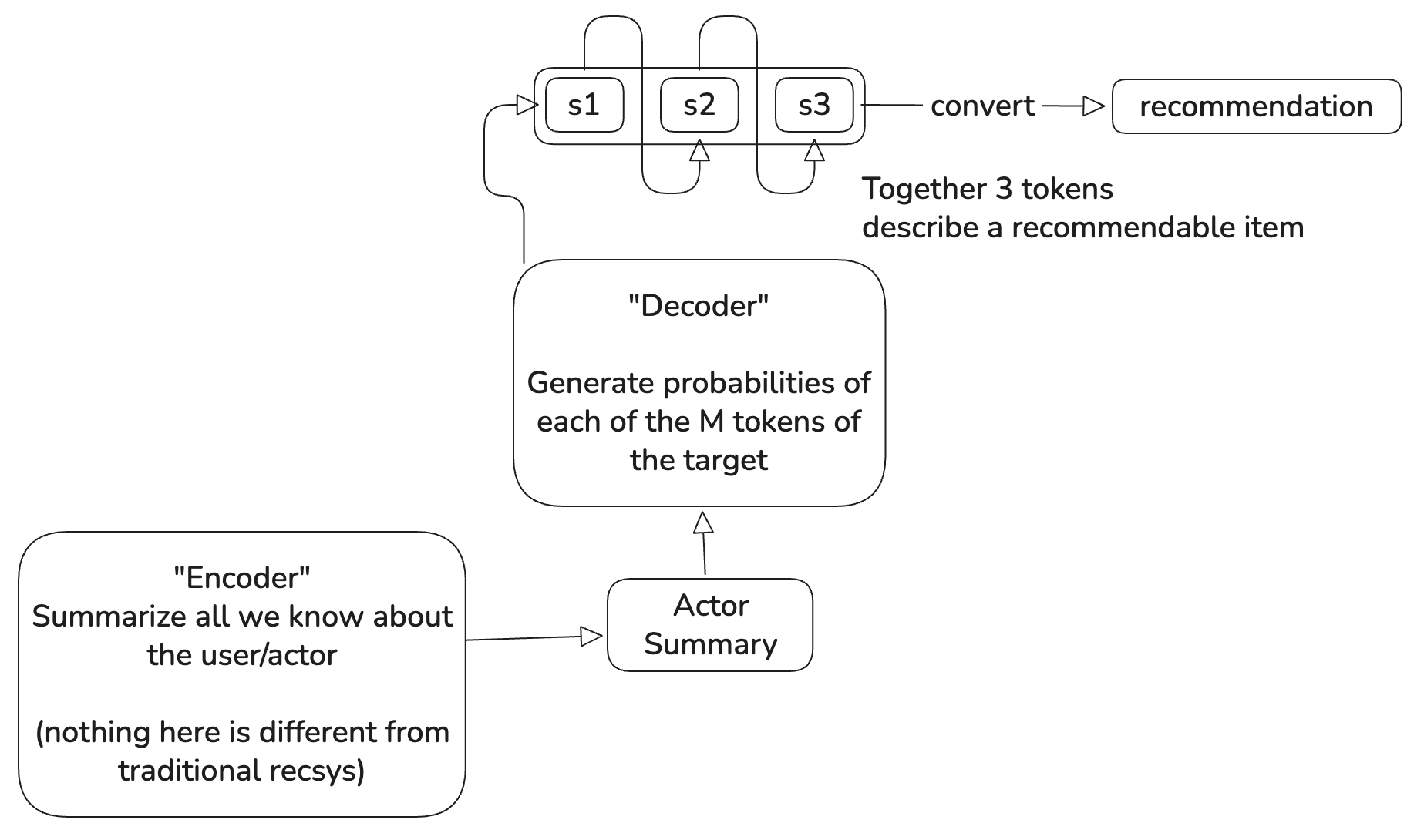
Let’s start with an overall schematic not including reward modeling since that is not changing for Friend-Recs.
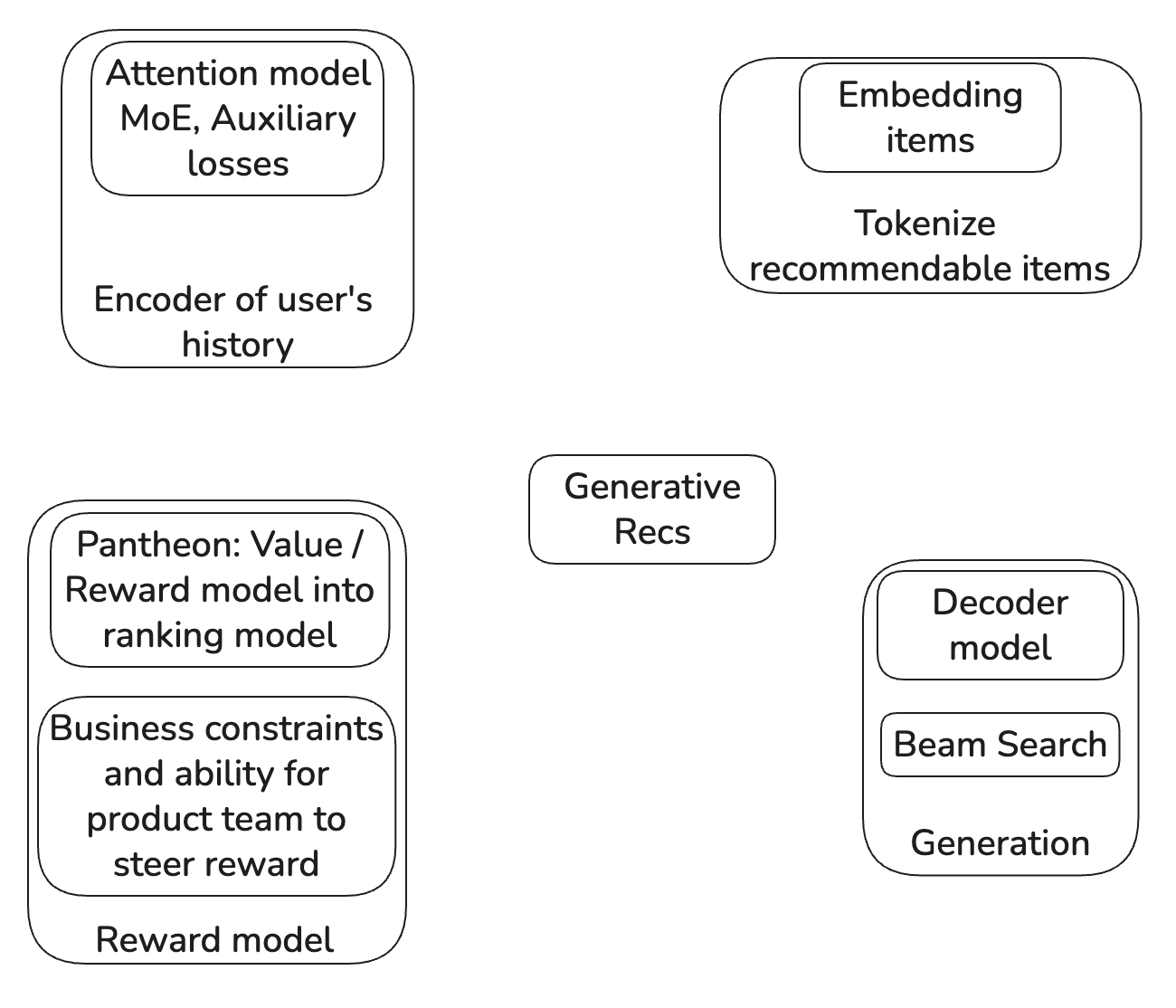
Parts of OneRec
Tokenization of recommendable items to make a “vocabulary” of a few thousand items for LLM-like generation to reliably train.
Semantic Embeddings: This a sort of high dimensional post code for each recommendable item which captures similarity in this domain.
Multi-stage “coarse-to-fine” clustering to create tokens of the item. This is similar to an e-commerce product catalog or the Yahoo.com homepage in 2000s!
Note that if your recsys has less than 100K items, you can skip this step and just use ids as tokens.
How to summarize user history (a.k.a. “Encoder”)
There is no use of tokens in OneRec’s encoder4. In some ways it is actually simpler than HSTU by Zhai et al, a state of the art user history encoder from Meta.
What I appreciate is how they have designed it using the standard LLM block of Self-Attention —> FeedForward block, enabling common Triton kernels and infra optimization from LLMs to be used.
How to generate (a.k.a. “Decoder”)
This uses the summary of step 2 using Cross-Attention and a decoder block to generate the tokens of the recommended item one token at a time.
Please note that this is not enough to produce high quality recommendations. The below quote from OneRec
" The pre-trained model only fits the distribution of the exposed item space through next token prediction, and the exposed items are obtained from the past traditional recommendation system. "
indicates that reward modeling and preference alignment are critical. We are not going further into them in this post because they stay largely the same in Friend-Recs.
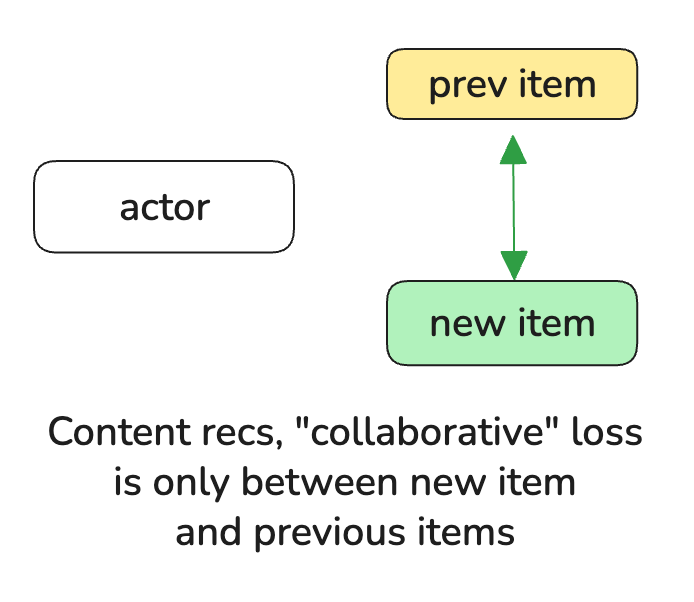
How Generative Friend-Recs differs from Generative Video-Recs.
The process of creating Semantic Embeddings is different because the “item” is also a “user”.
Closeness is 3-way and not 2-way
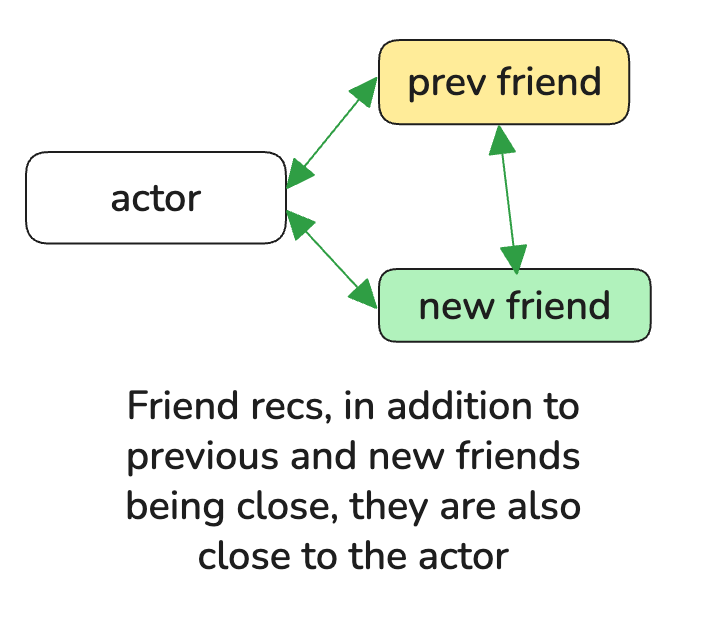
Grounding in demographic features / entities relevant to use case.

Training losses - Basically more losses per training example since we have 1000X fewer examples
Problems:
Unlike video recs where platforms have 10+ billion video watches to train from every day, friend recommendations are fewer.
We have two embeddings to learn: item id embedding and semantic id (STU) embedding. We need more signal.
Solution for problem #2, we add two other losses. Fig 7 —> Fig 8.

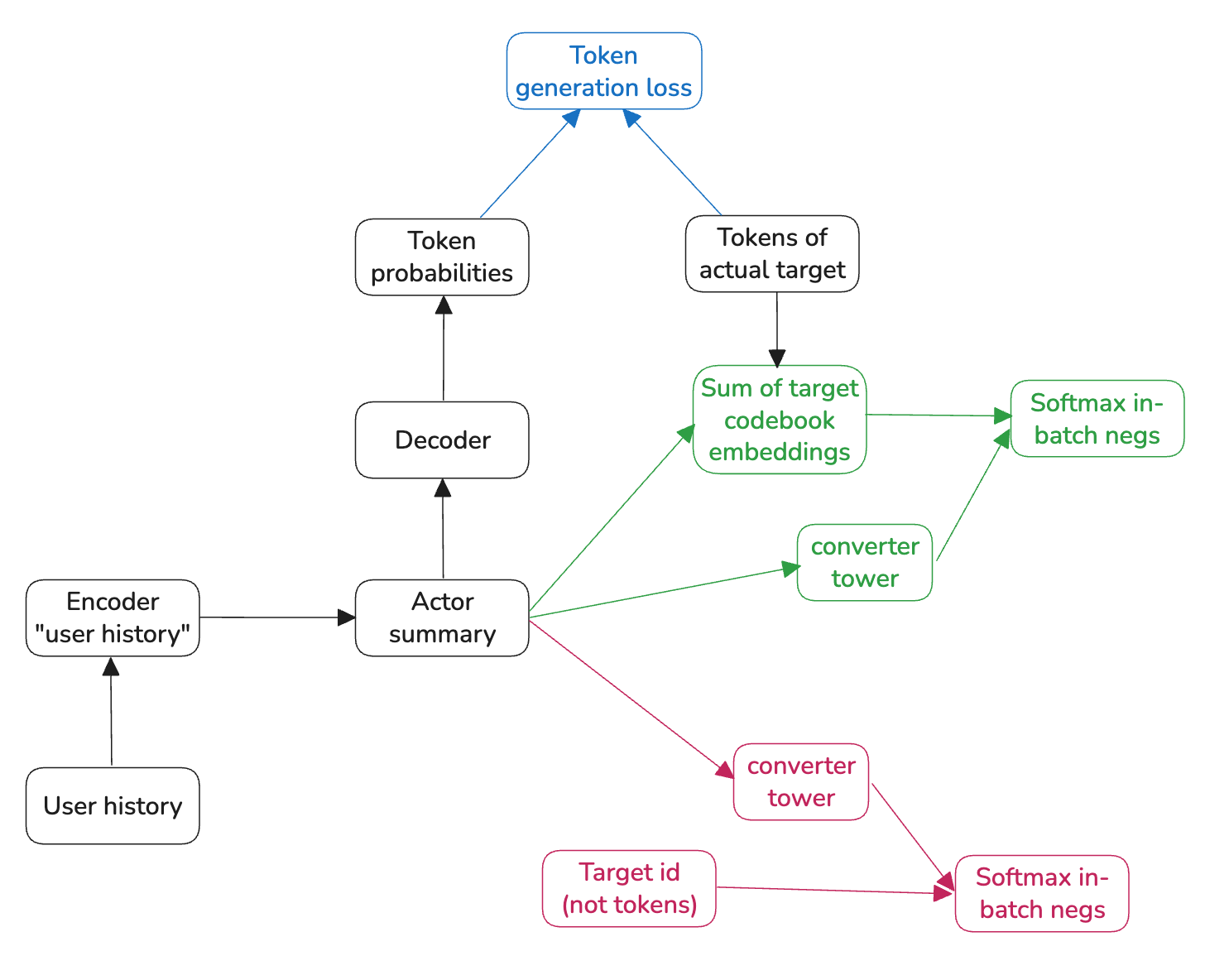
Summary:
True token generation loss is the classification loss for the target.
In-batch softmax loss from the codebook embeddings of the target can help separate true positives from weak negatives.
In-batch softmax loss from the id embeddings of the target can help in providing addition signal for id-representation learning. These embeddings are use in the encoder.
Solution for problem #1, Pretraining from user history splices and compute potentially all three losses for this spliced target. Schematic in Fig 9 and losses below.
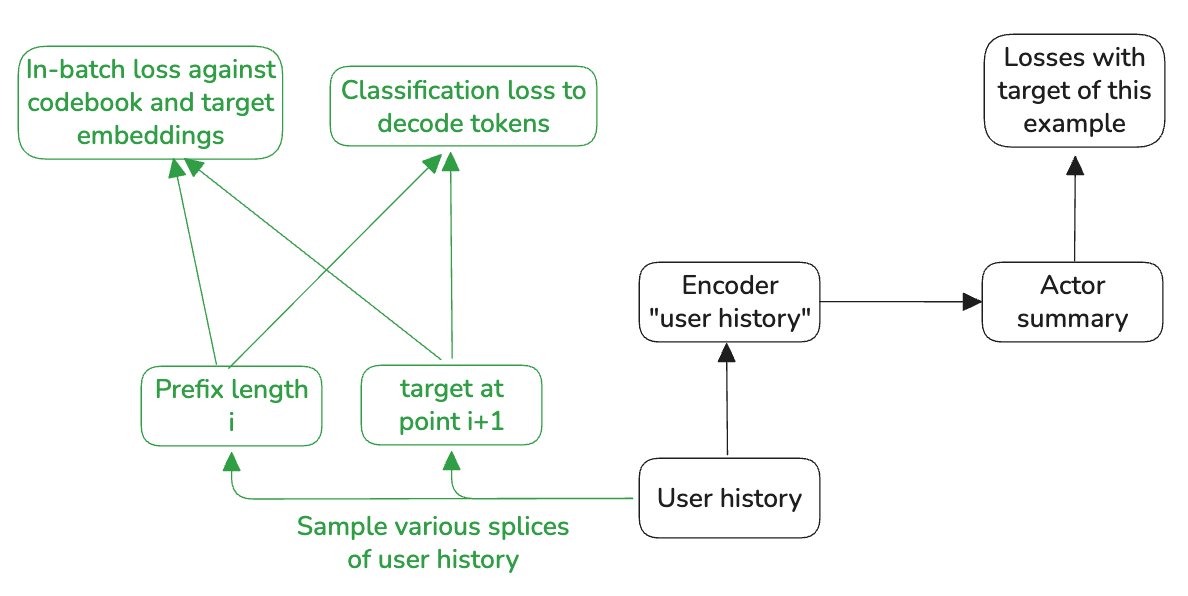
1. Temporal Autoregressive Loss L_{AR} - (true token generation loss for spliced history)
What it does: Predicts the next STU tokens (social tokenized user IDs) of the target user at time t+1, given the actor’s history up to t.
How:
Encoder produces h_i (hidden state for actor’s history prefix up to step i).
A classification head:
Linear(d_model, Codebook_size C)outputs logits for each of the M STU tokens of the target user.Compute cross-entropy between predicted logits and the actual target tokens.
👉 Trains:
Encoder parameters.
The classification heads.
2. Target’s codebook embeddings : L_{code}
What it does: Encourages the semantic codebook embeddings Z to represent users well in a contrastive sense.
How:
For the true target user at step i+1, we take its STU token embeddings z_{t_{i+1}} (e.g., by summing/averaging its M codebook vectors).
Compare with h_i using an InfoNCE / sampled softmax style loss against in-batch negatives.
👉 Trains:
Encoder (so h_i is predictive).
Codebook embeddings Z directly.
3. Target’s id embeddings : L_{target}
What it does: Makes the encoder’s hidden state h_i useful for directly predicting the continuous target embeddings e_{t_{i+1}} (from the user embedding table).
How:
Contrastive similarity between h_i and the “target” embedding e_{t_{i+1}}, with in-batch negatives.
👉 Trains:
Encoder (so its hidden states align with ground-truth future interactions).
Continuous embedding table {e_j} for all users.
Summary of Solution to Problem #1:
L_{AR}: trains M classification heads + encoder (discrete token prediction).
L_{code}: trains encoder + codebook embeddings Z.
L_{target}: trains encoder + continuous target embeddings {e_i}.
Conclusion: It’s a no brainer to invest in generative recs given the results from OneRec and others. This post shows one approach to building generative recommendations in a social recommendation use case. Hope it helps you in your use case.
Disclaimer: These are the personal opinions of the author(s). Any assumptions, opinions stated here are theirs and not representative of their current or any prior employer(s). Apart from publicly available information, any other information here is not claimed to refer to any company including ones the author(s) may have worked in or been associated with.
I did not mention “Reward Modeling” since it is different between any two recsys, even two video recommenders, since it is a representation of each product’s market fit. So the difference is not because of this being a friend recommender system.
Why? Why can’t we use a billion sized vocabulary? Short answer is, even if we could find enough GPUs for it, training will overfit and produce poor recommendations.
Disclaimer: As elaborated in Table 12 of OneRec, while generative OneRec is an improvement over multi-stage recsys, OneRec with Reward model which means using OneRec as a candidate generator is currently much better. It is still open research to make the generative model competent enough to not need a Reward model layer after it.
This is a simplification. As shown in section 4.2.2 of OneRec, they have also experimented with representing the history in terms of semantic ids and not item ids. They are actually seeing improved results but this will be packaged in a separate publication. We choose to call User Encoder unchanged since evidently in OneRec using semantic ids in User Encoder is not essential and this helps us hone in on the core innovation.