Ranking model calibration in recommender systems
We define calibration of ranking models in calibration, the benefit it can bring to prioritize calibration and how to achieve it without affecting normalized cross entropy / AUC metrics.


We show the importance of calibration in ranking models and how to implement it efficiently.
Context setting
Most recommender systems have a multi-task estimator model that estimates the probability of various user actions on the recommendation. After that there is usually a “value model” (a.k.a. multi-task fusion) to combine these into a single score to rank by. However, as we will show below the emitted probabilities might not be calibrated (explained below) with the observed probabilities.
Fixing model calibration can improve the topline metrics of your recsys.
(see benefit section)

Optional Context: For readers interested in late stage ranking, various aspects have been covered in
Code & Video
PTAL code here: github - gauravchak/calibration_arch_in_ranking_mtml
What will calibration bring you in recsys?
But hang on … you say, while these “late stage ranking” models are trained against binary user labels with binary cross entropy loss, we don’t really need them to be actual probabilities right, since there is value model on top of it.
And yes you would be right technically, if this isn’t ads ranking or feed blending you don’t really need the outputs to be probabilities. Any score that is comparable between two options should work to order them. However, since you have a value model (a.k.a. Multi-task fusion model), to combines these scores, calibration provides a sort of decoupling, a contract if you will about the scale and distribution between your model and your value model.
Without calibration, many of your ranking model accuracy improvements will fail to be launched because they are changing the scale / distribution especially for some country or user cohort. This will make your experiments look unintentionally soft in metrics.
In addition, since the goal of calibration is to provide the true likelihood of the predicted outcomes it can indeed help your ranking. Wouldn't you prefer to put at the top 1 position what you believe has the highest likelihood? For example Youtube found that using calibration increased their search CTR by 0.66%. This might seem small but in the context of a model like Youtube this is not a small feast!
Microsoft found similar results for the context of search retrieval. They also argue that this helps to find a threshold when not to show results for a query.
Prior work & Insights
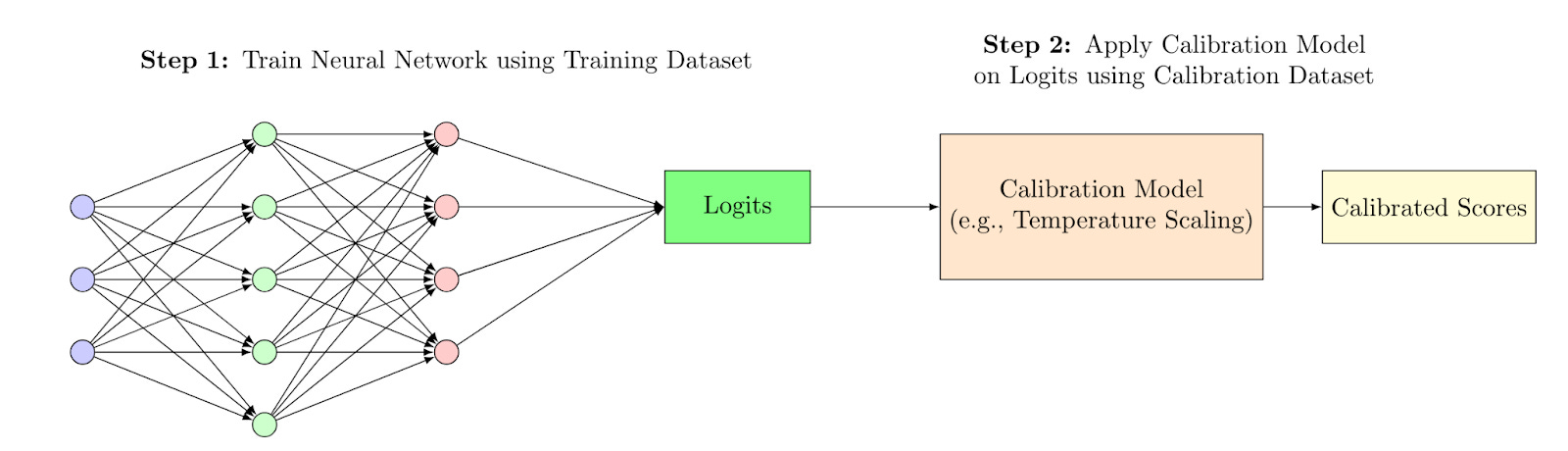
1. Post trained model on logits
In the most classical approaches, calibration is often applied as a post-training step; training a specific model on the logits of the first model using an independent dataset [1]. For example in On Calibration of Modern Neural Networks, Guo et al. leverage the idea of using a calibration model to improve the reliability of probability estimates from classification models using the temperature to do the calibration.
An advantage of this method is that by using an independent dataset and not the training dataset of your first model that created the logit it should generalize better on new data. One obvious disadvantage is that it complicates your overall architecture and training a second model can be costly. In addition, scalability can quickly become an issue if you wish to ensure calibration on different features. But don’t worry as with anything with machine learning there are other ways!
2. Loss function
In Regression Compatible Listwise Objectives for Calibrated Ranking with Binary Relevance, Google explores how creating a scale-calibrated multi-objective loss function can not only allow you to increase calibration but also benefit your ranking score in a listwise context. Interestingly, in this paper they argue that using a multi-objective where one is for ranking and the second is for calibration is not always compatible. More precisely, they prove that the common loss used (sigmoid for regression and softmax for ranking) actually pushes the gradient scores in different directions. Therefore, we will not cover others multi-objectives as a means for calibration here.
Also please note that for pointwise there are also ways to include calibration as part of the loss.

3. Layer
Another way to achieve calibration is by introducing a last layer into your network that achieves the calibration for you. For example, Linkedin created an Isotonic Calibration Layer for their ranker which helped increase offline and online metrics. In the repository, we also included a layer to represent Platt scaling.

Which one to pick?
As with everything in life.. It depends. Every problem is different, are you doing a listwise loss? Are you working on a retrieval system? Is scale an issue for you? Do you want to add a bayesian layer at the end of your model to do some exploration? Do you have a pointwise or listwise loss?
Sadly there is no one solution that fits all. And to be frank, this does not cover all the different ways to do calibration to start with. The importance as with everything is to start with something easy, test it and gradually make it better.
Defining calibration
1. Overall calibration (per task)
For each task the average value of the predicted probability of the task should match the average value of the observed probability.
2. Calibration on each prediction bucket/bin
It is possible that your model overpredicts or underpredicts at some ranges of the prediction.
For instance if you make 5 equal buckets of the eval dataset based on the predicted labels and compare the average values of the predicted label and observed task, do you see some buckets where there is significant gap in prediction vs observation?


3. Calibrated per user-cohort (or in general based on a feature)
Here we are concerned where your multi-task model might be overall well calibrated but could be mis-calibrated for certain cases. For instance:
You are building a music recommender system and your system could be under-calibrated for “timeless classics”. That means for timeless classics the predicted probability of listening might be lower than what you observe in data.
You are building a video recommender system where the training data is dominated by short videos and you find that you could be under predicting the probability of “like” on longer videos.
Implementation suggestions for calibrated ranking
Platt Scaling
In src/platt_scaling_calibration.py we show an option of adding Platt Scaling to improve Overall Calibration .
# in init: set the weight and bias for Platt Scaling
self.weights = nn.Parameter(torch.zeros(num_tasks))
self.bias = nn.Parameter(torch.zeros(num_tasks))
# during inference: computing task estimates
calibrated_logits = self.weights * ui_logits + self.biasAdd a loss to improve calibration per prediction bucket
In src/prediction_buckets_calibration.py, we add a loss based on #2 “Calibration on each prediction bucket/bin”. To do that, we compute the mean squared error (MSE) between the mean of the label and the mean of the prediction in each equally spaced bucket/bin (like histogram) of the prediction values.
# Compute ECE-MeanSquaredError loss
# These steps have been verified in this google colab
# Sigmoid to go from logits to predicted probabilities
preds: torch.Tensor = torch.sigmoid(ui_logits)
# Assuming preds and labels are of shape [B, T], sort preds to get indices. sorted_indices[0, t] would then be the index (from 0 to B-1) corresponding to the smallest value of the predicted probabilities of the t_th task.
sorted_indices: torch.Tensor = torch.argsort(preds, dim=0)
# Hence sorted_preds[i, t] is the i-th smallest predicted probability
sorted_preds: torch.Tensor = torch.gather(input=preds, dim=0, index=sorted_indices)
# sorted_labels[i, t] is the corresponding label
sorted_labels: torch.Tensor = torch.gather(input=labels.float(), dim=0, index=sorted_indices)
# Compute the mean prediction in each bin
pred_mean_per_bin: torch.Tensor = torch.matmul(self.scale_proj_mat, sorted_preds) # [PB, T]
# Compute label_mean in the bucket
label_mean_per_bin: torch.Tensor = torch.matmul(self.scale_proj_mat, sorted_labels) # [PB, T]
# Compute MSE between mean label and prediction in the bucket.
# First compute per task. This will allow us to later reuse any task specific weights set by the user for cross_entropy_loss.
mse_per_task: torch.Tensor = ((pred_mean_per_bin - label_mean_per_bin)**2).mean(dim=0)
calibration_loss: torch.Tensor = mse_per_task.mean()Note
ECE is defined with absolute deviation but we have chosen to use mean squared error in this implementation.
Verified Uncertainty Calibration shows that ECE has some bias. However, we think the drawback is not considerable.
Making sure the model is calibrated for different user cohorts
In src/feature_based_calibration.py, we add a loss that captures calibration for both values of a given feature. Imagine you are building a friend recommendation application and you want to ensure that your ranking model works for both new users and tenured users. By setting a feature “is_tenured”, this code shows how to ensure your models are calibrated for both tenured and new users.

Debiasing model arch against a feature
In src/feature_bias_capture.py, we are not trying to add a loss. We are adding a model architecture component, a shallow tower if you will, that computes each task logit purely based on the single feature and then adds the main task logits to it.
Appendix
Note on nomenclature: Calibration here is different from Steck (2018).
What we are referring to as calibration is different from what Harald Steck refers to here. In that paper, he is suggesting that if you observe the user’s prior interest in some categories, by ensuring your current slate of recommendations match the user’s prior distribution, you will not be under or over predicting a category. Here we are talking about matching the rate of the observed true label in your predictions.
Disclaimer: These are the personal opinions of the author(s). Any assumptions, opinions stated here are theirs and not representative of or attributable to their current or any prior employer(s). Apart from publicly available information, any other information here is not claimed to refer to any company including ones the author(s) may have worked in or been associated with.
 | A guest post by
|
Thanks for sharing your insight in calibration. I enjoyed reading it. One thing I don’t quite get is why we can calibrate within the model (i.e. adding layers or change loss), since the training data might be up/down sampled or weighted to account for imbalance, or in general any other filters. If we calibrate within the model, then it calibrates to the distribution of training data which is still biased?